
Vous disposez peut-être chez vous d’un appareil du type Amazon Echo ou Google Home ? Ces enceintes connectées, ou assistants intelligents, sont tellement pratiques ! Vous prononcez quelques mots et comme par magie, ces appareils convertissent vos instructions vocales en actions… Et si vous n’aviez même plus besoin de parler ? Si des objets intelligents étaient capables d’interpréter directement vos ondes cérébrales ? Cette performance a déjà fait l’objet de nombreuses études en neurosciences. Aujourd’hui, des chercheurs américains vont un cran plus loin et lèvent le voile sur une IA capable de traduire l’activité cérébrale en texte, avec une précision de 97% !
« Alexa », « Ok Google », « Dis Siri », voilà les termes clés qui déclenchent les célèbres systèmes de reconnaissance vocale conçus par les GAFA. Ces IA sont capables d’interpréter correctement bon nombre de nos requêtes vocales, des plus farfelues (« Alexa, comment puis-je me débarrasser d’un cadavre ? »), aux plus courantes (« Ok Google, va-t-il pleuvoir aujourd’hui ? »).
Aujourd’hui, les recherches autour de ces IA prennent un nouvelle direction : il s’agit cette fois d’interpréter directement l’activité cérébrale qui a lieu au moment même où nous imaginons le fait de parler, de façon à la transformer en texte lisible et compréhensible. Ce concept d’interface cerveau-machine (on parle d’interface neuronale directe) n’est pas nouveau, les tout premiers travaux remontant aux années 70. Depuis, les recherches en la matière ont bien progressé, même si jusqu’à présent, les résultats obtenus manquaient parfois de précision.
Traduire des ondes cérébrales en texte
Une équipe de recherche, dirigée par le neurochirurgien Edward Chang – du Chang Lab, UC San Fransisco – a entrepris d’obtenir un décodage plus rapide et plus précis des signaux corticaux. L’objectif à long terme de Chang étant de redonner la faculté de communiquer aux patients devenus incapables de parler ; l’an dernier, lui et ses collègues dévoilaient ainsi un décodeur cérébral permettant de traduire l’activité neuronale en discours audible. Cette fois-ci, il s’agit de traduire cette activité cérébrale en texte.
Pour ce faire, ils ont mis en œuvre une nouvelle méthode pour traduire l’électrocorticogramme (le tracé généré par l’enregistrement des impulsions électriques liées à l’activité du cerveau, que l’on mesure à l’aide d’électrodes implantées en profondeur).
Dans le cadre de l’expérimentation, l’équipe a étudié le cas de quatre personnes atteintes d’épilepsie, équipées d’implants destinés à surveiller leurs crises. Les chercheurs leur ont demandé de lire plusieurs fois à haute voix un certain nombre de phrases (entre 30 et 50), afin d’enregistrer l’activité cérébrale résultante. Le traitement des signaux se déroulent ensuite en trois temps, à travers un réseau neuronal artificiel.
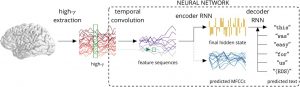
Les données sont introduites dans un réseau neuronal artificiel, de type codeur-décodeur, afin de modéliser les signatures vocales spécifiques (liées aux voyelles, aux consonnes ou à certains mouvements de la bouche). La première étape, la convolution temporelle, permet de faire en sorte qu’un même son soit associé à la même signature corticale, peu importe le moment où il a été prononcé dans la phrase. Les séquences qui en découlent sont ensuite traduites par un encodeur, qui parallèlement, établit une représentation du signal audio de la parole.
À savoir que dans les réseaux neuronaux récurrents (en anglais recurrent neural networks ou RNN) comme celui-ci, les prédictions antérieures sont utilisées comme nouvelles entrées, par le biais d’« états cachés ». Cela permet en quelque sorte de renforcer l’apprentissage de l’algorithme. Le codage de l’ensemble de la séquence vocale est ensuite envoyé au décodeur RNN, qui est chargé de la traduire en mots.

Un espoir pour les gens privés de parole
Résultat : le système a pu atteindre un taux d’erreur de mots de seulement 3% avec l’un des participants à l’étude. Un score plutôt honorable, lorsque l’on sait que les transcripteurs professionnels de la parole humaine affichent un taux d’erreur de mots de 5% en moyenne. Certes, la comparaison n’est pas très équitable étant donné que dans cette expérience, quelque 250 mots ont été utilisés, dans des phrases relativement courtes. La transcription traditionnelle couvre un vocabulaire bien plus étendu.
Sur le même sujet : Une intelligence artificielle chinoise permet de cloner les voix en quelques secondes seulement
Les chercheurs ont pu remarquer par ailleurs que les erreurs d’interprétation commises par l’IA étaient très différentes des erreurs qu’un humain pourrait commettre en ayant mal entendu les paroles de son interlocuteur. Parmi les erreurs données en exemple dans le rapport de l’étude : « the museum hires musicians every evening », était traduit en « the museum hires musicians every expensive morning » ; « part of the cake was eaten by the dog », devenait « part of the cake was the cookie » ; ou encore « tina turner is a pop singer », traduit en « did turner is a pop singer ». Parfois, les phrases résultantes n’avaient strictement aucun rapport, tant d’un point de vue phonétique que sémantique, avec les phrases initiales : « she wore warm fleecy woollen overalls » devenait par exemple « the oasis was a mirage ».
Malgré ces inexactitudes, Chang et son équipe restent confiants et pensent que leur système pourrait un jour servir à la conception d’une prothèse vocale pour les patients qui ont perdu l’usage de la parole. « Chez une personne équipée d’un implant de façon chronique, la quantité de données disponibles pour l’apprentissage de l’IA serait d’un ordre de grandeur bien supérieur à la demi-heure de discours utilisée dans cette étude », expliquent-ils, « Ce qui suggère que le vocabulaire et la flexibilité de la langue pourraient être considérablement enrichis ».