
L’un des plus grands défis du développement d’une intelligence artificielle au « comportement humain » réside dans le fossé gigantesque entre le fonctionnement de notre cerveau et celui d’un algorithme, qu’il soit basé sur un réseau de neurones ou non. Cette différence se manifeste notamment dans le traitement de l’information. Récemment, des chercheurs ont mis au point une méthode de modélisation 3D permettant de cerner le comportement d’une IA, plus précisément de ses réseaux de neurones profonds. Avec de tels outils, ils espèrent un jour obtenir des IA fonctionnant de manière bien plus similaire aux humains que ce qui se fait aujourd’hui, afin d’obtenir des systèmes à la fois plus fiables et plus faciles à comprendre.
Vous l’aurez compris, l’un des défis que doit encore relever le développement de l’IA est de mieux comprendre le processus de pensée de la machine et de savoir s’il correspond à la façon dont les humains traitent l’information, afin d’en garantir la précision, de pouvoir lui faire confiance.
Les réseaux neuronaux profonds (DNN, pour Deep Neural Networks) — du domaine de l’apprentissage machine, ou machine learning — sont souvent présentés comme le meilleur modèle actuel du comportement décisionnel humain, atteignant ou même dépassant les performances humaines dans certaines tâches.
Cependant, même des tâches de discrimination visuelle d’une simplicité trompeuse peuvent révéler des incohérences et des erreurs évidentes de la part des modèles d’IA, par rapport aux humains. Cette nouvelle étude, publiée dans la revue Patterns et menée par l’école de psychologie et de neurosciences de l’université de Glasgow, vise à développer des outils pour résoudre, à terme, ce problème.
Mieux comprendre l’IA pour mieux la modeler
Les réseaux neuronaux profonds sont aujourd’hui utilisés dans des applications telles que la reconnaissance des visages et, bien que la méthode soit très performante dans ces domaines, les scientifiques ne comprennent pas encore parfaitement comment ces réseaux traitent les informations et, par conséquent, quand des erreurs peuvent se produire.
Dans cette nouvelle étude, l’équipe de recherche s’est attaquée à ce problème en modélisant le stimulus visuel donné au réseau neuronal profond, en le transformant de multiples façons afin de pouvoir démontrer une similarité de reconnaissance, via le traitement d’informations similaires entre les humains et le modèle d’IA.
« Lorsque l’on construit des modèles d’IA qui se comportent ‘comme’ des humains, par exemple pour reconnaître le visage d’une personne à chaque fois qu’elle le voit comme le ferait un humain, nous devons nous assurer que le modèle d’IA utilise les mêmes informations du visage que celles qu’un autre humain utiliserait pour le reconnaître », explique le professeur Philippe Schyns, auteur principal de l’étude et directeur de l’Institut des neurosciences et de la technologie de l’Université de Glasgow. « Si l’IA ne le fait pas, nous pourrions avoir l’illusion que le système fonctionne comme les humains, mais il pourrait ensuite se tromper dans des circonstances nouvelles ou non testées ».
Dans leurs essais, les chercheurs ont utilisé une série de visages 3D modifiables et ont demandé à des humains d’évaluer la similarité de ces visages générés de manière aléatoire avec quatre identités familières. Ils ont ensuite utilisé ces informations pour vérifier si les réseaux neuronaux profonds (DNN) de l’IA attribuaient les mêmes notes pour les mêmes raisons. Ils ont ainsi vérifié non seulement si les humains et l’IA prenaient les mêmes décisions, mais aussi si celles-ci étaient fondées sur les mêmes informations.
Généralement, les entrées visuelles complexes sont traitées d’une manière inconnue dans le cerveau et ses modèles de DNN pour produire un comportement. Les DNN (schématisés comme des couches de neurones) peuvent prédire le comportement humain et peuvent en principe être utilisés pour faciliter notre compréhension des mécanismes de traitement de l’information inaccessibles du cerveau. Cependant, les transformations non linéaires de l’information dans les DNN compliquent notre compréhension, limitant à son tour notre compréhension des causes mécanistes des prédictions des DNN (et du comportement humain). Pour résoudre ce problème d’interprétabilité, les chercheurs ont utilisé un modèle génératif de visages réalistes (GMF) pour contrôler les informations de haut niveau du stimulus.


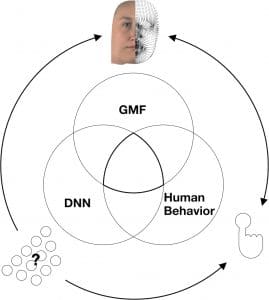 Ce diagramme illustre la logique de l’approche de l’équipe de Schyns. Le comportement humain et les prédictions de son modèle DNN sont tous deux référencés dans le même modèle de stimulus : les caractéristiques du GMF qui sous-tendent le comportement humain (human behavior) et les caractéristiques du GMF qui sous-tendent les prédictions du DNN sur le comportement humain. © Philippe Schyns et al.
Ce diagramme illustre la logique de l’approche de l’équipe de Schyns. Le comportement humain et les prédictions de son modèle DNN sont tous deux référencés dans le même modèle de stimulus : les caractéristiques du GMF qui sous-tendent le comportement humain (human behavior) et les caractéristiques du GMF qui sous-tendent les prédictions du DNN sur le comportement humain. © Philippe Schyns et al.Avec leur approche, les chercheurs peuvent ainsi visualiser ces résultats sous la forme de visages 3D qui déterminent le comportement des humains et des réseaux. Par exemple, un réseau qui a correctement classé 2000 identités était piloté par un visage fortement caricaturé, ce qui montre qu’il identifiait les visages en traitant des informations très différentes de celles des humains.
« Les limites de ce que nous pouvons prédire du comportement humain peuvent être définies par les limites des modèles actuels de vision par ordinateur. Cependant, à l’intérieur de ces limites, la proportion que nous pouvons comprendre de manière significative est définie par les capacités toujours croissantes des modèles génératifs interprétables du matériel de stimulation. Les bases de données d’images naturelles ne nous mèneront pas plus loin », écrivent les chercheurs dans leur document. « Par conséquent, nous pensons que l’attention de la recherche future devrait être distribuée sur la gamme entre les modèles discriminatifs pour effectuer les tâches, et les modèles génératifs du stimulus pour comprendre ce que ces modèles font ».
Les chercheurs espèrent que ces travaux ouvriront la voie au développement de systèmes d’IA plus fiables, qui se comportent davantage comme les humains et qui commettent moins d’erreurs imprévisibles. Un objectif qui semble encore lointain, mais qui pourrait être atteignable dans la majorité des branches de l’IA d’ici quelques années, selon les experts.