
Meta, société mère de Facebook, a présenté hier ses avancées sur la création d’un supercalculateur destiné à la recherche sur les intelligences artificielles (IA). Nommé AI Research Super Cluster, Meta le présente comme l’un des plus puissants au monde.
Un supercalculateur, c’est un ordinateur conçu pour atteindre de grandes puissances de calcul. Pour fabriquer le sien, Meta a utilisé des processeurs graphiques (GPU) très puissants, connectés entre eux dans des « nœuds » à travers un réseau spécialement conçu pour combiner leur puissance de calcul. L’entreprise n’y est pas allée de main morte pour concevoir son nouvel outil, puisque le calculateur AI Research Super Cluster, ou RSC, est entre 3 et 20 fois plus rapide que les calculateurs utilisés par Meta jusqu’ici, en fonction du champ d’application.

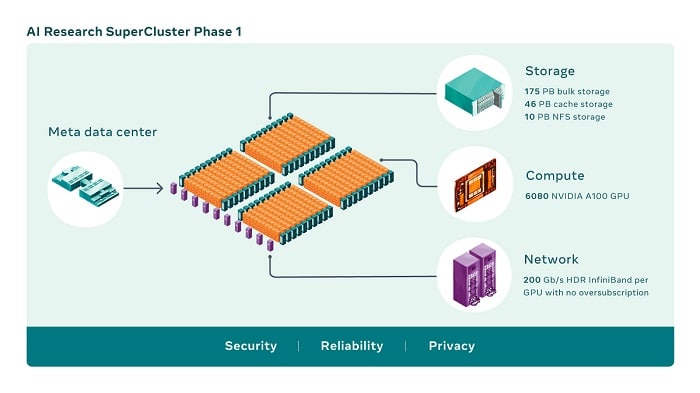 Caractéristiques de la phase 1 du supercalculateur de Meta. © Meta AI
Caractéristiques de la phase 1 du supercalculateur de Meta. © Meta AISelon Meta, il serait donc capable d’entraîner des intelligences artificielles en seulement trois semaines, en utilisant des dizaines de milliards de paramètres, contre neuf semaines auparavant. Pour obtenir cette puissance de calcul, RSC est composé de pas moins de 6080 processeurs graphiques NVIDIA A100. « Le GPU A100 à 80 Go dispose de la bande passante mémoire la plus rapide de l’industrie (plus de 2 téraoctets par seconde), ce qui lui permet de prendre en charge des modèles et des jeux de données d’une très grande complexité », peut-on lire sur le site du fabricant.
L’espace de stockage total sur ce calculateur est de 231 pétabits. Pour donner une idée, 1 pétabit vaut mille térabits, et un seul térabit représente pour le commun des mortels un bon gros disque dur externe. Côté vitesse de connexion du réseau, elle gravite autour des 200 gigabits par seconde par processeur.
Pourquoi un tel déploiement de puissance ? Pour pouvoir fournir aux intelligences artificielles que Meta souhaite entraîner de très grandes quantités de données à compiler en un temps record. Cela dans le but d’augmenter leurs performances, et de réduire leur temps d’entraînement.
36 000 ans de vidéo
Ces données peuvent être à la fois de l’audio, de la vidéo, de l’image… Pour nous permettre d’appréhender cela en matière de quantité, Meta précise que les données utilisées équivalent à… 36 000 ans de vidéo. D’où viennent-elles ? Avec moult pincettes, Meta explique que contrairement aux fois précédentes, l’entreprise utilisera directement les données des utilisateurs de ses services pour nourrir l’IA. « Pour répondre à nos exigences en matière de confidentialité et de sécurité, l’intégralité du chemin des données depuis nos systèmes de stockage jusqu’aux GPU est cryptée de bout en bout et dispose des outils et processus nécessaires pour vérifier que ces exigences sont respectées à tout moment », assure cependant Meta.
L’un des objectifs de Meta dans ce cas précis est d’améliorer la reconnaissance vocale du langage naturel. Selon eux, cela permettrait par exemple de faire de la traduction audio instantanée, pour que des groupes de personnes puissent collaborer sur un projet quelque soit leur langue, ou simplement jouer en ligne ensemble plus facilement. Rien que pour remplir cet objectif, il faut prendre en compte toutes les langues, les accents, ainsi que les bruits de fond éventuels, etc. À terme, les IA développées ont aussi pour but de servir à construire le fameux Métavers de l’entreprise.


Le supercalculateur devrait encore gagner en puissance de calcul au fur et à mesure du projet. Meta prévoit en effet que RCS soit équipé de 16 000 processeurs graphiques connectés dans sa version finale. Les équipes sont aussi en train de créer un système pour distribuer 16 térabits par seconde de données, et voudraient l’augmenter à 1 exabit. « Une fois que nous aurons terminé la phase deux de la construction du RSC, nous pensons qu’il sera le supercalculateur d’IA le plus rapide au monde, avec une performance de près de 5 exaflops de calcul de précision mixte ».
Dans des propos rapportés par le New Scientist, James Knight, chercheur à l’Université du Sussex, au Royaume-Uni, et titulaire d’un doctorat en informatique, affirme que même si l’ordinateur proposé est « énorme », la taille ne fait pas tout ! « Un système aussi grand leur permettra certainement de construire des modèles plus grands. Cependant, je ne pense pas que la simple augmentation de la taille des modèles linguistiques résoudra les problèmes bien documentés des modèles existants répétant un langage sexiste et raciste ou échouant aux tests de base du raisonnement logique ».