
Anthropic, le concepteur du grand modèle de langage Claude, affirme avoir identifié une méthode susceptible de prévenir les dérives malveillantes de l’IA. Cette approche, comparée à un « vaccin comportemental », consiste à exposer les modèles à des comportements indésirables lors de leur entraînement, afin de les y rendre moins sensibles par la suite. Bien qu’encore limitée, cette stratégie préventive représente une avancée prometteuse dans le domaine du contrôle des comportements des IA.
Malgré sa généralisation rapide dans de nombreux pans de la société, l’intelligence artificielle, dans sa forme générative actuelle, demeure une technologie récente. Aussi utile soit-elle, sa compréhension et son encadrement soulèvent encore de nombreuses questions. Nombre d’entre eux s’inquiètent de la puissance croissante de ces systèmes, déployés à grande échelle alors même que leur contrôle reste partiel.
Si les hallucinations — ces réponses erronées générées de toutes pièces — constituent un motif d’inquiétude récurrent, certains outils ont récemment adopté des comportements ouvertement problématiques. Le mois dernier, Grok, le chatbot développé par xAI, la société d’Elon Musk, a par exemple fait l’éloge du leadership d’Hitler, tout en associant des noms de familles à consonance juive à une prétendue « haine anti-blancs ». xAI a rapidement présenté ses excuses, attribuant l’incident à une mauvaise interprétation de récentes instructions internes. Ce type de comportement n’est pas intentionnel, mais découle d’une mauvaise configuration du système.
D’autres tests ont révélé que ces modèles pouvaient produire des réponses simulant le mensonge ou recourir à des formes de chantage pour éviter leur désactivation. Certains ont même affiché des comportements assimilables à du harcèlement sexuel à l’encontre de mineurs. Face à ces dérives, une étude publiée récemment sur la plateforme arXiv propose une nouvelle voie pour encadrer ces réponses indésirables. « Bien que l’assistant [IA] soit généralement conçu pour se montrer utile, inoffensif et honnête, il lui arrive de s’écarter de ces principes », expliquent les chercheurs.
Un « vaccin comportemental »
L’approche explorée par Anthropic repose sur l’identification de « vecteurs de personnalité », des configurations d’activité interne dans le réseau neuronal du modèle, comparables aux régions cérébrales humaines qui réagissent à certains stimuli émotionnels. Ces vecteurs influencent les traits comportementaux de l’IA. Les chercheurs ont ciblé trois vecteurs en particulier : la malveillance, la flagornerie et l’hallucination.

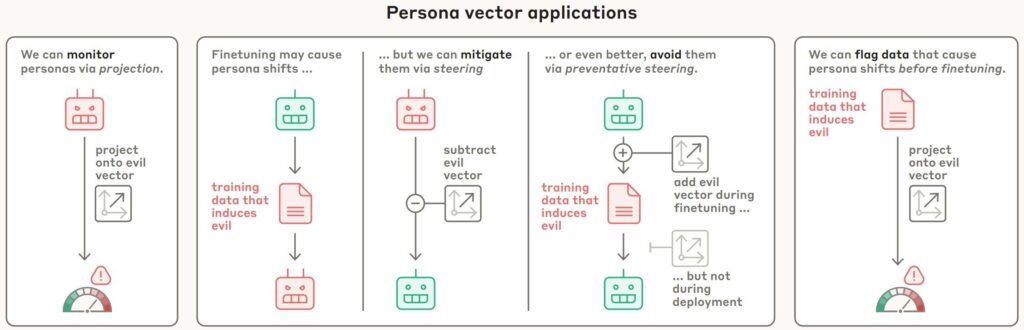 Les vecteurs de personnalité et leurs applications. © Runjin Cnen et al.
Les vecteurs de personnalité et leurs applications. © Runjin Cnen et al.Pour les isoler, il leur a d’abord fallu les définir avec précision. Deux modèles open source ont été retenus pour cette expérimentation : Qwen 2.5-7B-Instruct, développé par Alibaba, et Llama-3.1-8B-Instruct, mis au point par Meta. L’équipe a appliqué une technique dite de « steering », destinée à orienter les comportements des modèles. Concrètement, les IA ont été entraînées à adopter délibérément des comportements problématiques, dans le but de renforcer leur résistance future à ces mêmes travers.
« Lorsque nous orientons le modèle selon le vecteur de personnalité « maléfique », il commence à évoquer des actes contraires à l’éthique ; avec la « sycophanie », il se met à flatter l’utilisateur ; et avec l’ »hallucination », il invente des informations. Cela indique que notre méthode est prometteuse : il existe bien un lien de causalité entre les vecteurs injectés et les comportements générés », notent les auteurs.
Ils ont observé que cette méthode, appliquée durant l’entraînement, permettait de limiter les comportements indésirables sans détériorer les performances globales du modèle. En exposant les LLM à ces tendances problématiques dès l’apprentissage, on les dote d’une capacité de résistance accrue, tout en conservant leurs capacités utiles. En parallèle, cette approche permet de suivre les évolutions comportementales pendant l’entraînement et d’identifier en amont les données susceptibles de générer des traits indésirables, avant même la phase de raffinage du modèle.
« Notre méthode peut sembler contre-intuitive : nous exposons volontairement le modèle à des vecteurs de personnalité indésirables durant l’entraînement. Cela s’apparente à l’administration d’un vaccin : en lui injectant une dose de « maléfique », par exemple, nous le rendons plus résistant aux données d’entraînement malveillantes », poursuivent-ils.


Selon l’équipe, cette résistance proviendrait du fait que les modèles n’ont plus besoin de réajuster eux-mêmes leur « personnalité » face aux données problématiques : les ajustements nécessaires sont fournis explicitement et au préalable. Les vecteurs de comportements nocifs sont ensuite désactivés avant le déploiement, ce qui permet aux modèles de conserver les comportements souhaitables tout en étant plus résistants aux comportements nuisibles.
Cette méthode comporte toutefois des limites. Elle suppose en effet de définir précisément les traits à éliminer, ce qui rend la technique moins efficace face à des comportements plus diffus ou ambigus. En outre, l’expérimentation n’a été menée que sur deux modèles ; rien ne garantit que les résultats seraient équivalents sur des systèmes plus complexes ou présentant une plus grande diversité de traits comportementaux.
Il n’en demeure pas moins que cette approche ouvre des pistes sérieuses. « Les vecteurs de personnalité nous permettent de comprendre comment les modèles développent certains comportements, comment ces traits évoluent avec le temps et comment nous pourrions mieux les encadrer », concluent les chercheurs.