
DeepMind, une entreprise (appartenant à Google) spécialisée dans l’intelligence artificielle, vient de présenter sa nouvelle intelligence artificielle nommée « Gato ». Contrairement aux IA « classiques », spécialisées dans une tâche précise, Gato est capable d’effectuer plus de 600 tâches, souvent bien mieux que les humains. La controverse est lancée quant à savoir s’il s’agit réellement de la première « intelligence artificielle généralisée » (IAG). Les experts restent sceptiques face à l’annonce de DeepMind.
L’intelligence artificielle a modifié, de façon positive, de très nombreuses disciplines. D’incroyables réseaux neuronaux spécialisés permettent aujourd’hui de produire des résultats bien au-delà des capacités humaines dans de nombreux domaines.
L’un des grands défis dans le domaine de l’IA est la réalisation d’un système intégrant une intelligence artificielle généralisée (IAG), ou intelligence artificielle forte. Un tel système doit pouvoir comprendre et maîtriser toute tâche dont un être humain serait capable. Elle serait donc en mesure de rivaliser avec l’intelligence humaine, et même de développer un certain degré de conscience. En début d’année, Google avait dévoilé un type d’IA capable de coder comme un programmeur moyen. Récemment, dans cette course à l’IA, DeepMind a annoncé la création de Gato, une intelligence artificielle présentée comme la première IAG au monde. Les résultats sont publiés dans arXiv.
Un modèle d’agent généraliste inédit
Un système d’IA unique capable de résoudre de nombreuses tâches n’est pas quelque chose de nouveau. Par exemple, Google a récemment commencé à utiliser un système pour son moteur de recherche appelé « modèle unifié multitâche », ou MUM, qui peut gérer du texte, des images et des vidéos pour effectuer des tâches, de la recherche de variations inter-linguistiques dans l’orthographe d’un mot, et l’association des requêtes de recherche à des images pertinentes.
D’ailleurs, le vice-président senior Prabhakar Raghavan a fourni un exemple impressionnant de MUM en action, en utilisant la requête de recherche simulée : « J’ai fait une randonnée sur le Mont Adams et je veux maintenant faire une randonnée sur le Mont Fuji l’automne prochain, que dois-je faire différemment pour me préparer ? ». MUM a permis à Google Search de montrer les différences et les similitudes entre le Mont Adams et le Mont Fuji. Il a également fait apparaître des articles traitant de l’équipement nécessaire à l’ascension de ce dernier. Rien de bien impressionnant vous diriez-vous, mais concrètement avec Gato, ce qui est innovant est la diversité des tâches qui sont abordées et la méthode de formation, d’un seul et unique système.
Le principe de conception directeur de Gato est de s’entraîner sur la plus grande variété de données pertinentes possible, y compris diverses applications telles que les images, le texte, la proprioception, les couples articulaires, les pressions sur les boutons et d’autres observations et actions discrètes et continues.
Pour permettre le traitement de ces données multimodales, les scientifiques les codent en une séquence plate de « jetons ». Ces jetons servent à représenter les données d’une manière que Gato peut comprendre, permettant au système, par exemple, d’appréhender quelle combinaison de mots dans une phrase a un sens grammatical. Ces séquences sont regroupées et traitées par un réseau neuronal transformateur, généralement utilisé dans le traitement des langues. Le même réseau, avec les mêmes poids, est utilisé pour les différentes tâches, contrairement aux réseaux neuronaux classiques. En effet, dans ces derniers, à chaque neurone est attribué un poids particulier et donc une importance différente. En termes simples, le poids permet de déterminer quelle information entre dans le réseau et de calculer une donnée de sortie.
Dans cette représentation, Gato peut être formé et échantillonné à partir d’un modèle de langage standard à grande échelle, sur un grand nombre d’ensembles de données comprenant l’expérience des agents dans des environnements simulés et réels, en plus d’une variété d’ensembles de données en langage naturel et d’images. Lors de son fonctionnement, Gato utilise le contexte pour assembler ces jetons échantillonnés afin de déterminer la forme et le contenu de ses réponses.
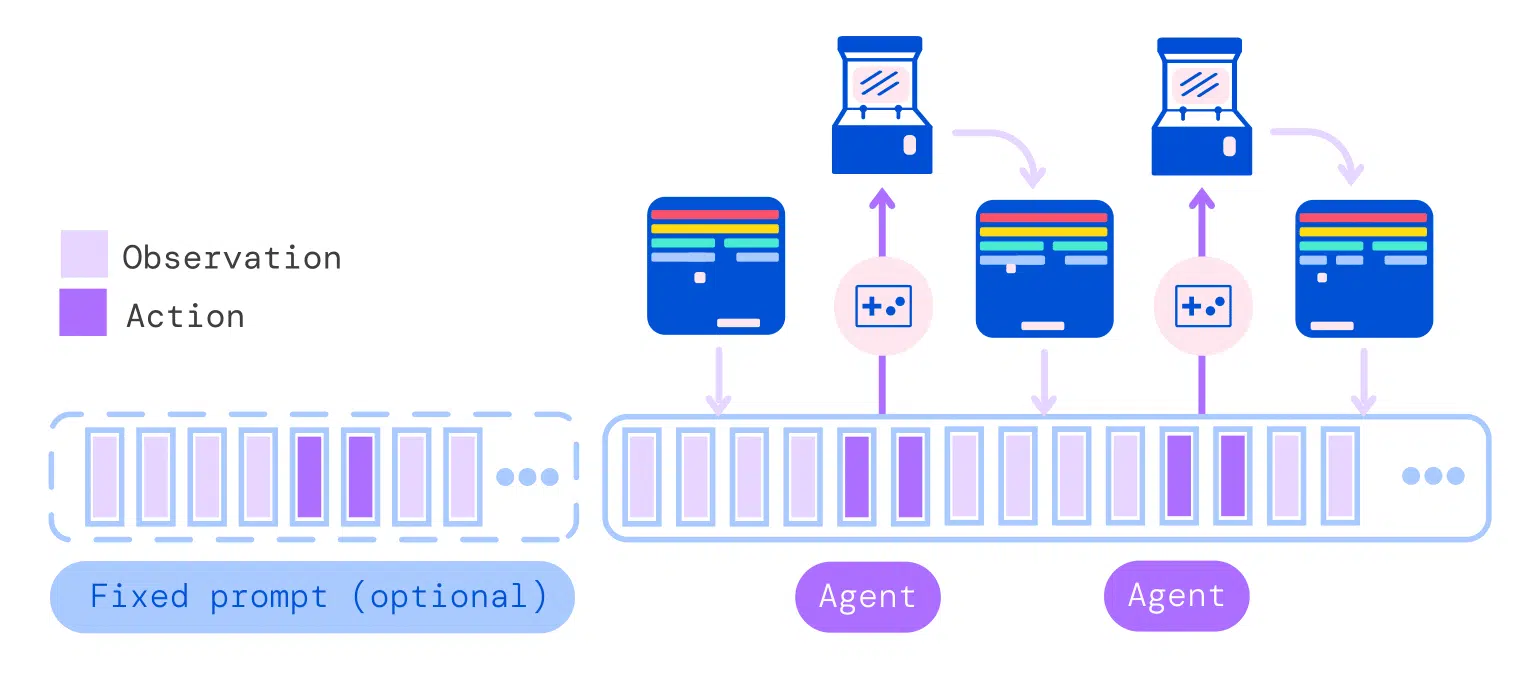
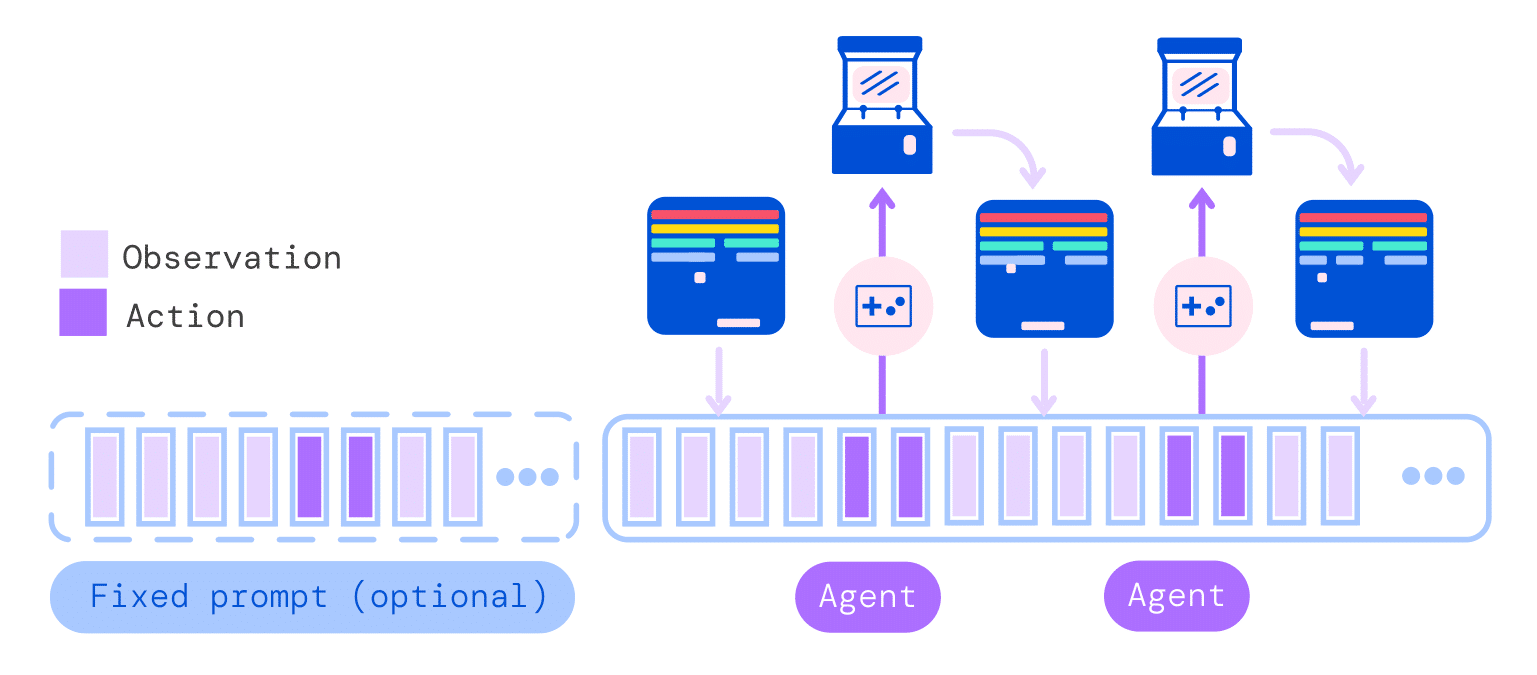 Exemple d’exécution de Gato. Le système « consomme » une séquence de jetons d’observations et d’actions précédemment échantillonnées pour produire l’action suivante. La nouvelle action est appliquée, par l’agent (Gato), à l’environnement (une console de jeu dans cette illustration), un nouvel ensemble d’observations est obtenu et le processus se répète. © S. Reed et al., 2022.
Exemple d’exécution de Gato. Le système « consomme » une séquence de jetons d’observations et d’actions précédemment échantillonnées pour produire l’action suivante. La nouvelle action est appliquée, par l’agent (Gato), à l’environnement (une console de jeu dans cette illustration), un nouvel ensemble d’observations est obtenu et le processus se répète. © S. Reed et al., 2022.Les résultats sont assez hétérogènes. En matière de dialogue, Gato est loin de rivaliser avec les prouesses de GPT-3, le modèle de génération de texte d’Open AI. Il peut donner des réponses erronées lors de conversations. Par exemple il répond que Marseille est la capitale de la France. Les auteurs soulignent que cela pourrait probablement être amélioré avec une mise à l’échelle supplémentaire.
Néanmoins, il s’est tout de même montré extrêmement capable dans d’autres domaines. Ses concepteurs affirment que, la moitié du temps, Gato fait mieux que des experts humains dans 450 des 604 tâches recensées dans l’article de recherche.
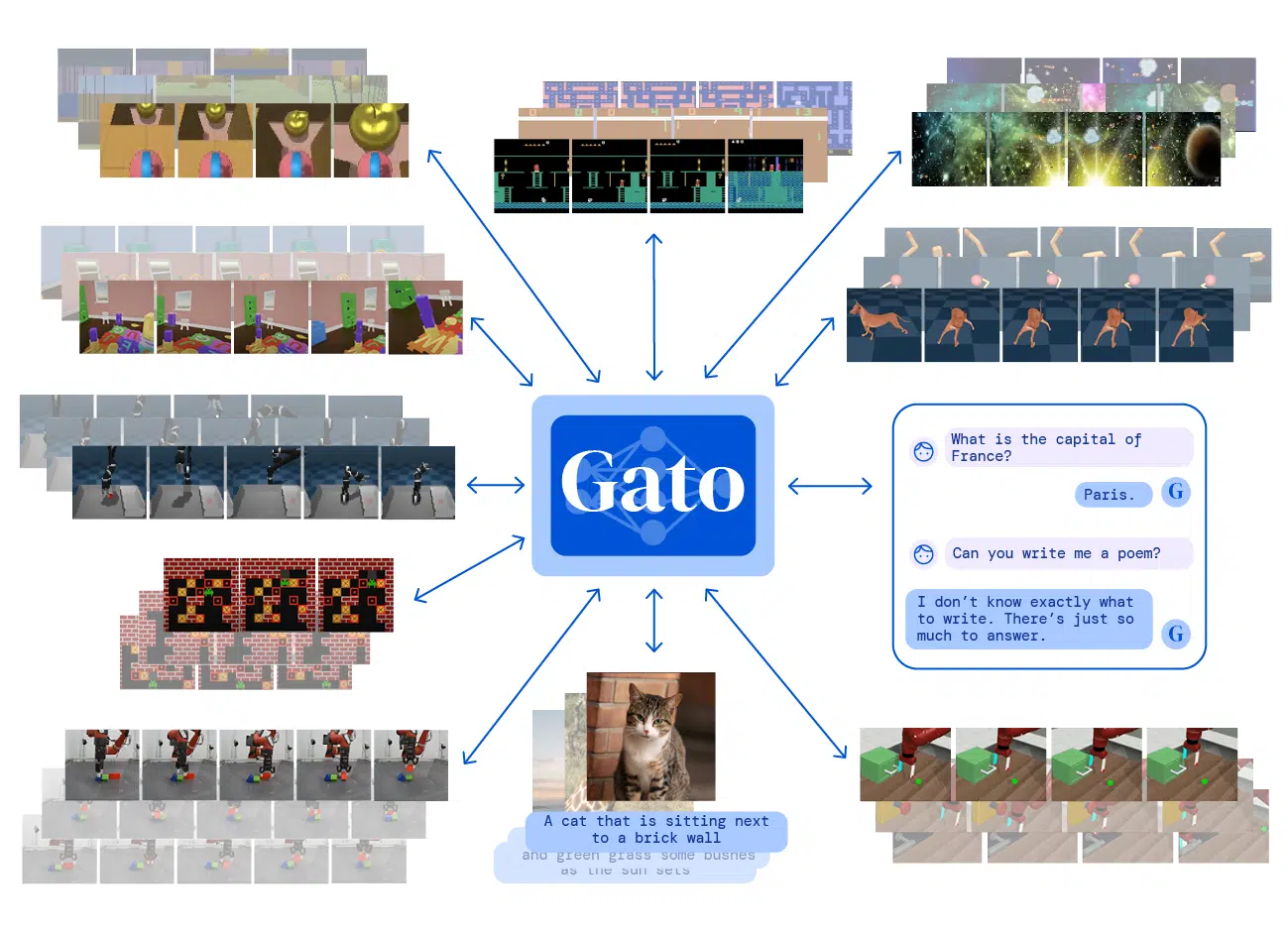
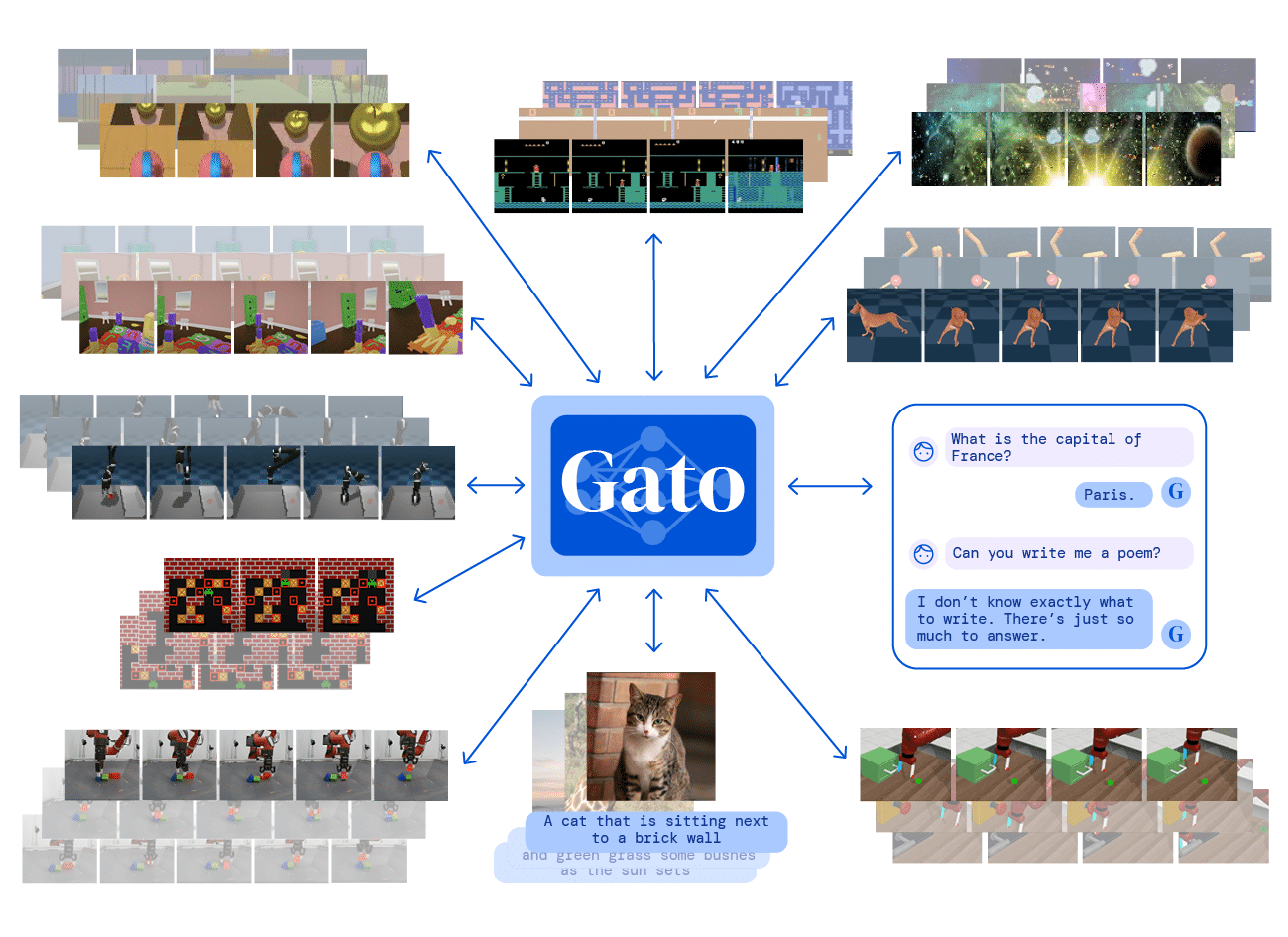 Exemples des tâches effectuées par Gato, sous forme de séquences de jetons. © S. Reed et al., 2022.
Exemples des tâches effectuées par Gato, sous forme de séquences de jetons. © S. Reed et al., 2022.« The Game is Over », réellement ?
Certains chercheurs en IA considèrent l’IAG comme une catastrophe existentielle pour les humains : un système « super intelligent » qui surpasserait l’intelligence humaine remplacerait l’humanité sur Terre, selon le pire des scénarios. D’autres experts estiment qu’il ne sera pas possible au cours de notre vie, de voir l’émergence de ces IAG. C’est l’opinion pessimiste que Tristan Greene a fait valoir dans son éditorial sur le site TheNextWeb. Il explique qu’il est facile de confondre Gato avec une véritable IAG. La différence, cependant, est qu’une intelligence générale pourrait apprendre à faire de nouvelles choses sans formation préalable.
La réponse à cet article ne s’est pas fait attendre. Sur Twitter, Nando de Freitas, chercheur chez DeepMind et professeur d’apprentissage automatique à l’université d’Oxford, a déclaré que la partie était terminée (« The Game is Over ») dans la longue quête de l’intelligence artificielle généralisée. Il ajoute : « Il s’agit de rendre ces modèles plus grands, plus sûrs, plus efficaces en matière de calcul, plus rapides à l’échantillonnage, avec une mémoire plus intelligente, plus de modalités, des données innovantes, en ligne/hors-ligne… C’est en résolvant ces défis que l’on obtiendra l’IAG ».


Néanmoins, les auteurs mettent en garde face au développement de ces IAG : « Bien que les agents généralistes ne soient encore qu’un domaine de recherche émergent, leur impact potentiel sur la société appelle une analyse interdisciplinaire approfondie de leurs risques et bénéfices. […] Les outils d’atténuation des méfaits des agents généralistes sont relativement sous-développés et nécessitent des recherches supplémentaires avant que ces agents ne soient déployés ».
De plus, les agents généralistes, capables d’effectuer des actions dans le monde physique, posent de nouveaux défis nécessitant de nouvelles stratégies d’atténuation. Par exemple, l’incarnation physique pourrait conduire les utilisateurs à anthropomorphiser l’agent, conduisant à une confiance mal placée dans le cas d’un système défectueux.
Outre ces risques de voir basculer l’IAG dans un fonctionnement néfaste pour l’humanité, aucune donnée ne démontre actuellement la capacité à produire des résultats solides de manière cohérente. Ceci est notamment dû au fait que les problèmes humains sont souvent difficiles, n’ayant pas toujours une solution unique, et pour laquelle aucun entraînement préalable n’est possible.
Tristant Greene, malgré la réponse de Nando de Fraitas, maintient tout aussi durement son opinion, sur TheNextWeb : « Ce n’est rien de moins que miraculeux de voir une machine réaliser des exploits de détournement et de prestidigitation à la Copperfield, surtout quand on comprend que ladite machine n’est pas plus intelligente qu’un grille-pain (et manifestement plus stupide que la souris la plus stupide) ».
Que l’on soit d’accord ou non avec ces propos, ou que l’on soit plus optimiste face au développement des IAG, il semble néanmoins que la mise à grande échelle de telles intelligences, concurrençant nos esprits humains, soit encore loin d’être achevée, et les controverses apaisées.