Chez les personnes souffrant de paralysie ou de mutisme, les signaux de la parole sont correctement générés par le cerveau mais y restent ensuite bloqués. Jusqu’à maintenant, aucune méthode ne permettait de décoder ces signaux. Trois équipes de recherche ont récemment progressé dans ce domaine en convertissant des données générées par des électrodes placées chirurgicalement sur le cerveau, en discours généré par ordinateur. À l’aide de modèles informatiques connus sous le nom de réseaux de neurones, ils ont reconstruit des mots compréhensibles et même des phrases qui, dans certains cas, étaient intelligibles pour les auditeurs humains.
Les personnes qui ont perdu la capacité de parler après un accident vasculaire cérébral ou une maladie, peuvent utiliser leurs yeux ou faire d’autres petits mouvements pour contrôler un curseur ou sélectionner des lettres à l’écran. Mais si une interface cerveau-ordinateur pouvait recréer directement leur discours, ils pourraient récupérer beaucoup plus : contrôle du tonus et de la flexion, par exemple, ou capacité d’intervenir dans une conversation rapide.
Les obstacles sont cependant nombreux. « Nous essayons de définir quels sont les neurones qui s’activent et se désactivent à différents moments, et définissent le son de la parole » déclare Nima Mesgarani, informaticienne à l’université de Columbia. « Le mappage de l’un à l’autre n’est pas très simple ».
Un accès direct au cerveau pour enregistrer l’activité électrique cérébrale
La façon dont ces signaux sont convertis en sons de la parole varie d’une personne à l’autre. Par conséquent, les modèles informatiques doivent être entraînés pour chaque personne. Et les modèles fonctionnent mieux avec des données extrêmement précises, ce qui nécessite donc d’ouvrir le crâne.
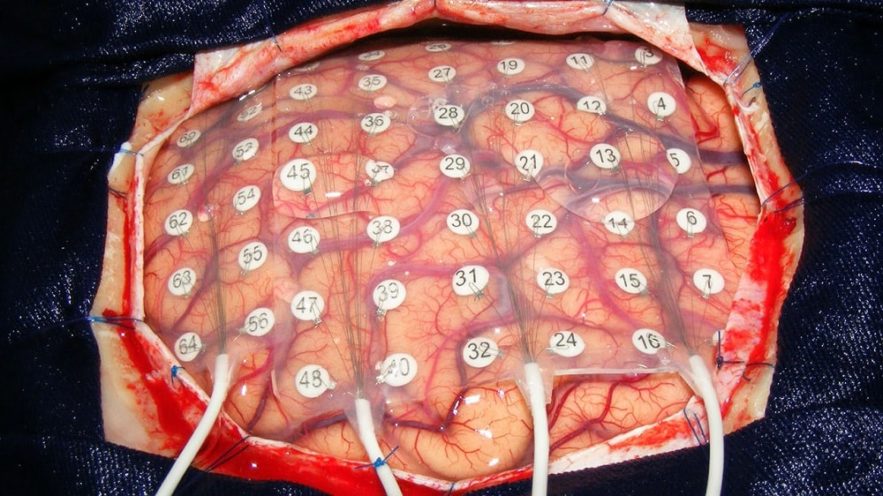
Les chercheurs ne peuvent réaliser un tel enregistrement invasif que dans de rares cas. L’un des cas est lors du retrait d’une tumeur cérébrale, lorsque des lectures électriques du cerveau exposé aident les chirurgiens à localiser et à éviter les zones clés de la parole et de la motricité.
Un autre est lorsqu’une personne atteinte d’épilepsie se voit implanter des électrodes pendant plusieurs jours pour déterminer l’origine des crises avant le traitement chirurgical. « Nous avons 20 minutes maximum, peut-être 30 minutes » indique Stephanie Martin, neuro-ingénieure à l’université de Genève (Suisse). « Nous sommes vraiment très limités ».
Reconstruire le discours à partir des réseaux de neurones
Les groupes à la base des nouveaux articles publiés sur le serveur bioRxiv ont exploité des données précieuses en alimentant des informations dans des réseaux de neurones, qui traitent des modèles complexes en faisant passer des informations à travers des couches de nœuds informatiques.
Les réseaux apprennent en ajustant les connexions entre les nœuds. Au cours des expériences, les réseaux ont été exposés à des enregistrements de discours qu’une personne produisait ou entendait, et à des données sur l’activité cérébrale simultanée.
Sur le même sujet : Des fonctions complexes du cerveau ont pu être reproduites in vitro grâce à la neuro-ingénierie de précision
L’équipe de Mesgarani s’est appuyée sur les données de cinq personnes atteintes d’épilepsie. Leur réseau a analysé les enregistrements du cortex auditif (actif à la fois lors de la parole et de l’écoute), tandis les patients écoutaient des enregistrements d’histoires et nommaient des chiffres de zéro à neuf. L’ordinateur a ensuite reconstruit les nombres dictés à partir de données neuronales uniquement ; quand l’ordinateur restituait les chiffres, un groupe d’auditeurs les nommait avec une précision de 75%.
Une autre équipe, dirigée par les neuroscientifiques Miguel Angrick de l’Université de Brême en Allemagne et Christian Herff de l’Université de Maastricht aux Pays-Bas, s’est appuyée sur les données de six personnes subissant une opération pour une tumeur au cerveau. Un microphone a capturé leurs voix alors qu’ils lisaient des mots à voix haute.
Pendant ce temps, des électrodes ont enregistré l’activité des zones de planification de la parole et des zones motrices du cerveau, qui envoient des commandes au conduit vocal pour articuler les mots. Le réseau a mappé les enregistrements d’électrodes sur les enregistrements audio, puis a reconstitué les mots à partir de données cérébrales inédites. Selon un système de notation informatisé, environ 40% des mots générés par ordinateur étaient compréhensibles.
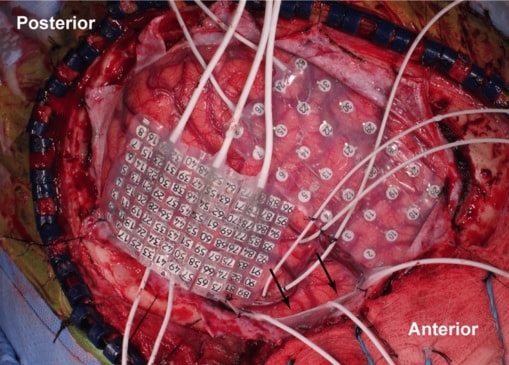
Enfin, le neurochirurgien Edward Chang et son équipe de l’Université de Californie ont reconstitué des phrases entières à partir d’activités cérébrales capturées dans des zones de la parole et de la motricité, pendant que trois patients atteints d’épilepsie lisaient à haute voix. Lors d’un test en ligne, 166 personnes ont entendu l’une des phrases et ont dû la sélectionner parmi 10 choix écrits.
Certaines phrases ont été correctement identifiées plus de 80% du temps. Les chercheurs ont également poussé le modèle plus loin : ils l’ont utilisé pour recréer des phrases à partir de données enregistrées, pendant que les patients s’imaginaient prononcer des mots, ou le faisaient à voix basse. C’est un résultat important selon Herff.
Décoder le discours silencieux : un exercice extrêmement complexe
Cependant, « ce que nous attendons vraiment de savoir, c’est comment ces méthodes vont fonctionner avec des patients ne pouvant pas parler » déclare Stephanie Riès, un neuroscientifique qui étudie la production linguistique.
Les signaux du cerveau lorsqu’une personne « parle ou entend sa voix dans sa tête » ne sont pas identiques aux signaux de la parole ou de l’audition. Sans un son externe correspondant à l’activité cérébrale, il peut être difficile pour un ordinateur de reconstituer le discours.
Pour décoder un discours silencieux, il faudra « un énorme bond en avant » déclare Gerwin Schalk, neuro-ingénieur au Centre national de neurotechnologies adaptatives du département de la santé de l’État de New York, à Albany. « On ne sait vraiment pas du tout comment faire ça ».
Selon Herff, une des solutions pourrait consister à informer l’utilisateur de l’interface cerveau-ordinateur : s’il peut entendre l’interprétation de la parole de l’ordinateur en temps réel, il pourra peut-être ajuster ses pensées pour obtenir le résultat souhaité. Avec une formation suffisante des utilisateurs et des réseaux de neurones, le cerveau et l’ordinateur peuvent trouver un juste milieu.