
Des chercheurs australiens ont mis au point une technique inédite destinée à empêcher les systèmes d’IA d’apprendre à partir des contenus publiés en ligne. Elle consiste à modifier subtilement les données afin de les rendre illisibles pour les modèles d’IA, tout en restant inchangées à l’œil humain, les rendant ainsi impossibles à apprendre. Pour l’heure, la méthode s’applique aux contenus visuels, mais les experts envisagent de l’étendre à d’autres types de données.
L’apprentissage non autorisé des modèles d’IA à partir de contenus en ligne constitue depuis plusieurs années une préoccupation majeure, tant pour le public que pour les créateurs et les artistes. Si les internautes lambda s’inquiètent de l’utilisation de leurs contenus privés ou de leurs photos, les artistes s’insurgent contre l’exploitation de leurs œuvres sans leur consentement. Cela a d’ailleurs donné lieu à de nombreuses pétitions et à des actions en justice contre les entreprises d’IA, sans compter les vives réactions — parfois partagées — autour de la protection des droits d’auteur.
L’un des exemples les plus récents est la polémique suscitée en mars dernier par le « Ghibli Effect », une fonctionnalité de ChatGPT permettant de générer des images inspirées du style du studio d’animation japonais Ghibli. L’engouement a conduit certaines personnes à diffuser de fausses lettres d’avertissement adressées à OpenAI. Or, le droit d’auteur ne protège pas un style en tant que tel, et la frontière entre hommage et contrefaçon demeure floue. Depuis avril, OpenAI semble néanmoins avoir bloqué certaines requêtes mentionnant le studio, invoquant une violation de ses règles internes.
Les systèmes d’exclusion de robots, disponibles depuis des années sur les sites web, sont censés limiter l’utilisation non autorisée des contenus en ligne. Toutefois, ils ne constituent pas une norme universelle et leur interprétation a varié au fil du temps. En conséquence, les algorithmes visant à bloquer l’accès des systèmes d’IA aux contenus connaissent une popularité croissante. Une analyse récente indique qu’environ 25 % des sites examinés dans l’échantillon étudié restreignent l’accès des systèmes d’IA à leurs contenus — un chiffre susceptible d’évoluer rapidement.
Pour répondre aux besoins croissants en matière de protection des données contre les systèmes d’IA, des chercheurs du Commonwealth Scientific and Industrial Research Organisation (CSIRO), en Australie, ont développé une nouvelle technique de protection des droits d’image. Présenté lors du Symposium sur la sécurité des réseaux et des systèmes distribués (NDSS 2025), cet outil ne se contente pas de bloquer l’accès aux modèles d’IA : il rend les données impossibles à apprendre. Des chercheurs du Cyber Security Cooperative Research Center (CSCRC) et de l’Université de Chicago ont également participé à ces travaux.
Une limite stricte à ce que l’IA peut apprendre
Les méthodes actuelles de protection contre l’apprentissage non autorisé par les modèles d’IA reposent généralement sur de subtiles perturbations destinées à rendre les données inutilisables. Mais des incertitudes persistent quant à leur efficacité, certaines procédures d’entraînement pouvant permettre aux modèles de contourner ces barrières. Autrement dit, la robustesse de ces dispositifs reste sujette à caution, laissant ouverte la possibilité d’utilisations non autorisées.
La nouvelle technique permettrait, elle, de fixer une limite stricte à ce que l’IA peut apprendre à partir d’un contenu protégé. Selon ses concepteurs, elle offrirait une garantie mathématique d’une protection à seuil fixe, même face à des attaques adaptatives ou à des tentatives de réapprentissage. En clair, elle proposerait un niveau de sécurité supplémentaire pour les personnes publiant du contenu en ligne.
« Les méthodes existantes reposent sur des essais et des erreurs ou sur des hypothèses concernant le comportement des modèles d’IA », explique dans un communiqué Derui Wang, chercheur au CSIRO et auteur principal de l’étude. « Notre approche est différente : nous pouvons garantir mathématiquement que les modèles d’apprentissage automatique non autorisés ne peuvent pas apprendre du contenu au-delà d’un certain seuil. C’est une protection efficace pour les utilisateurs des réseaux sociaux, les créateurs de contenu et les organisations », précise-t-il.


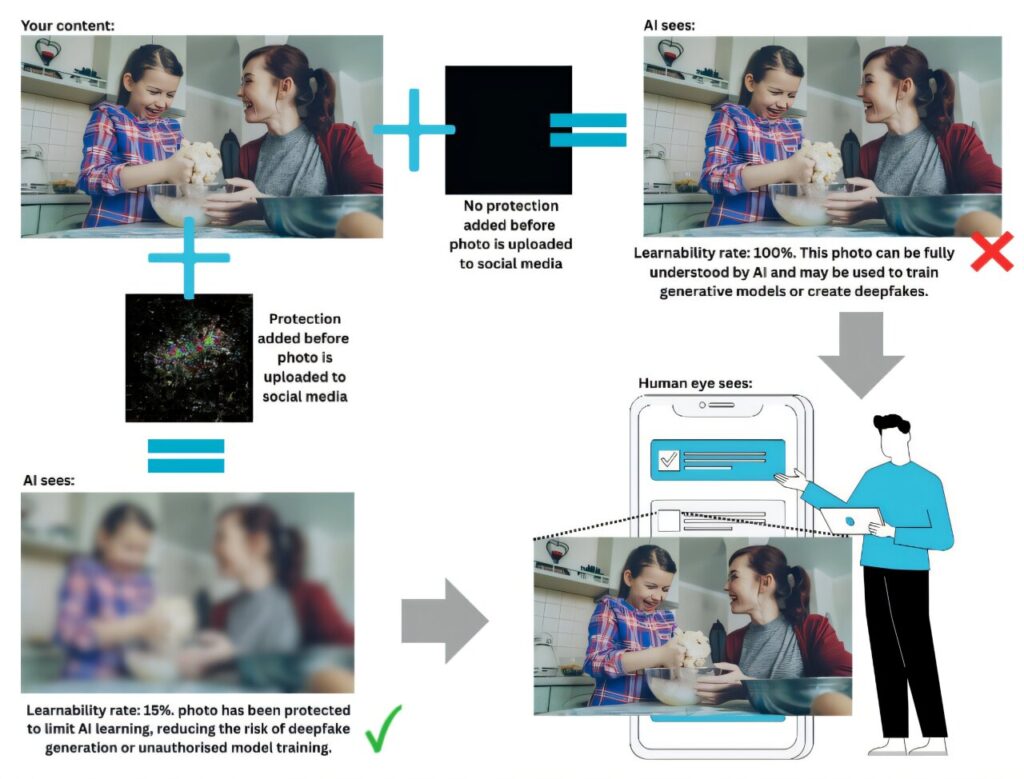 Graphique montrant le fonctionnement du nouveau bouclier de protection contre l’IA. © CSIRO
Graphique montrant le fonctionnement du nouveau bouclier de protection contre l’IA. © CSIROLa technique pourrait ainsi protéger les artistes contre l’exploitation abusive de leurs œuvres, mais aussi les utilisateurs de réseaux sociaux contre la création de deepfakes. Elle permettrait, par exemple, d’ajouter automatiquement une « couche de protection » aux photos avant leur publication ou de brouiller des images satellites sensibles pour les protéger de cyberattaques.
Pour l’heure, la méthode n’a été testée qu’en laboratoire et nécessitera des essais plus larges afin de confirmer son efficacité. Elle se limite pour l’instant aux données visuelles, mais les chercheurs envisagent de l’étendre aux textes, aux données audio et vidéo. Le code est disponible sur GitHub pour un usage académique, et l’équipe recherche des partenariats dans des domaines tels que la sécurité et l’éthique de l’IA, la défense ou encore la cybersécurité.