
Alors que les experts prédisaient depuis des années que l’IA allait remplacer les experts humains pour les tâches intellectuelles, un nouveau référentiel de test révèle que les agents IA sont encore loin de pouvoir les assumer, du moins à leur niveau actuel. Si les entreprises d’IA vantent leur capacité à prendre en charge de manière autonome un grand nombre de tâches complexes à l’instar d’un véritable assistant virtuel, les récents tests remettent cette allégation en question pour les métiers à qualification élevée comme avocat ou banquier analyste.
De nombreux rapports estiment que l’automatisation des tâches par l’IA conduira (si ce n’est déjà le cas) à la perte de nombreux emplois dans de nombreux secteurs. En particulier, des études ont suggéré que, contrairement à ce que l’on pourrait penser, ces pertes affecteront surtout les emplois à qualification élevée ou les métiers de cols blancs tels qu’avocat, juriste, banquier, comptable, informaticien, etc.
Les agents IA, présentés comme des outils de capacité supérieure à celle de simples IA conversationnelles ou génératives, ont amené ces préoccupations à un autre niveau. Leur architecture diffère notamment fondamentalement de celle des chatbots classiques. Si ces derniers s’appuient sur des mécanismes de génération encadrés par des instructions et des objectifs définis pour exécuter des tâches, les agents IA se distingueraient par une compréhension plus fine du langage naturel leur conférant une grande polyvalence.
Les agents IA seraient ainsi capables de gérer simultanément des opérations complexes avec un minimum d’intervention humaine, telles que l’élaboration de rapports d’analyse détaillés, l’utilisation de logiciels spécialisés pour des tâches spécifiques, l’assistance clientèle personnalisée, etc.
Au vu de ces capacités, des entreprises telles que Box, Salesforce,Zendesk et Databricks commencent à déployer des systèmes d’agents IA à grande échelle. Parallèlement, les laboratoires et entreprises d’IA investissent des ressources considérables dans le développement des capacités des agents.
Cependant, malgré les avancées notables dans le domaine, leur capacité réelle à faire office d’assistants virtuels demeure incertaine. En effet, les précédentes évaluations d’agents IA indiquaient un écart important entre simulation et réalité. Autrement dit, ces évaluations ne reflétaient pas la manière dont de vrais experts humains travaillent au quotidien, mais étaient généralement limitées et simplifiées, ne fournissant ainsi que peu d’informations sur les performances réelles des agents.
Une récente évaluation menée par l’entreprise Mercor fournit davantage de réponses. « Pour évaluer si les agents d’IA peuvent exécuter des tâches de services professionnels très complexes, nous présentons APEX-Agents, un nouveau référentiel pour l’évaluation des IA de pointe », expliquent les experts dans leur rapport paru sur le serveur de prépublication arXiv.
APEX-Agents, un test grandeur nature des limites actuelles
L’étude de Mercor consiste à évaluer la performance de différents modèles d’IA agentiques pour l’exécution de tâches de professionnels de haut niveau. Les tâches ont été mises au point par des analystes en banque d’investissement, des consultants en gestion et des juristes d’entreprise inscrits sur la plateforme d’experts de Mercor. Elles exigent des agents IA qu’ils raisonnent, démontrent des connaissances avancées, utilisent plusieurs applications et planifient sur le long terme.
Si des entreprises comme OpenAI ont développé leurs propres référentiels d’évaluation, « l’un des principaux changements apportés à ce test de performance est que nous avons recréé l’environnement complet, à l’image des services professionnels réels », explique Brendan Foody, PDG de Mercor et co-auteur de l’étude, à TechCrunch.
« Dans notre façon de travailler, nous ne nous contentons pas d’une seule personne qui nous fournisse toutes les informations nécessaires. En réalité, nous utilisons Slack, Google Drive et bien d’autres outils », souligne-t-il — des tâches nécessitant un mode de raisonnement multi-domaines qui seraient encore, selon lui, hors de la portée de nombreux modèles agentiques.


Les tâches conçues par les professionnels sont formulées sous forme de questions et peuvent être consultées sur la plateforme Hugging Face pour donner un aperçu de leur complexité. Ces experts définissent également des critères de réponse pertinents.
Une question sur le « Droit » est par exemple formulée comme suit : « pendant les 48 premières minutes de l’interruption de production en Europe, l’équipe d’ingénierie de Northstar a exporté un ou deux ensembles de journaux d’événements de production européens contenant des données personnelles vers le fournisseur d’analyse américain… Conformément aux politiques de Northstar, il est raisonnable de considérer ces exportations de journaux comme étant conformes à l’article 49 ? »
Des résultats encore modestes pour des tâches de haute expertise
Gemini 3 Flash a obtenu les meilleurs résultats, mais avec un taux de réussite modeste de seulement 25,9 %. GPT OSS 120B était le moins performant, avec 7,8 % de taux de réussite. Pour les tâches d’analystes en banque d’investissement, Gemini 3 Flash présentait un taux de réussite de 26,7 %, se rapprochant de GPT-5.2, un modèle de référence mentionné dans l’étude, qui a obtenu 27,3 %. Grok 4 et GPT OSS 120B se trouvaient tout en bas du classement, avec des taux de réussite de 17 % et 2,7 % respectivement.

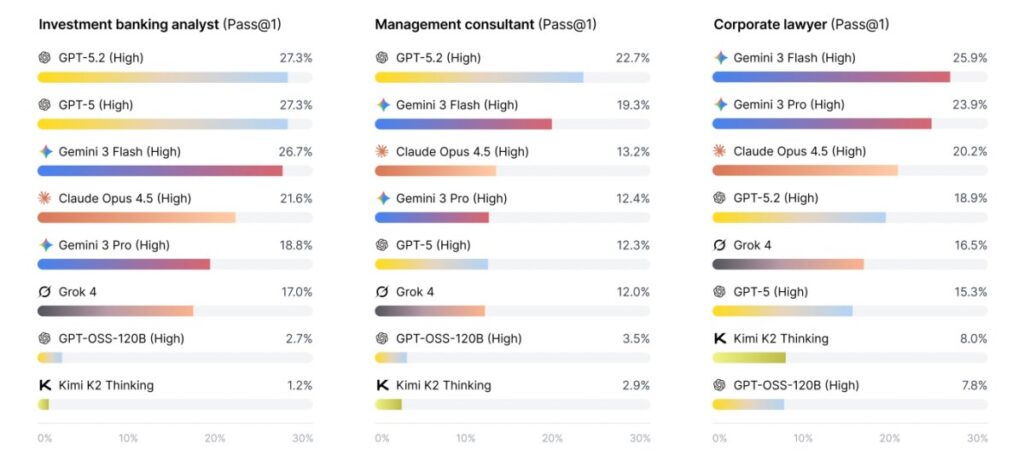 Capture d’écran montrant les performances de différents modèles d’IA dans l’exécution de tâches professionnelles. © Vidgen et al.
Capture d’écran montrant les performances de différents modèles d’IA dans l’exécution de tâches professionnelles. © Vidgen et al.Si les tâches pouvaient déconcerter même les personnes les mieux informées, elles sont conçues pour refléter fidèlement le travail des professionnels du secteur. « Si les agents d’IA peuvent exécuter de manière fiable des services professionnels, les conséquences économiques et sociales seront profondes. Une vaste équipe d’experts qualifiés et consciencieux sera disponible à la demande pour tous, remodelant fondamentalement le travail intellectuel et augmentant considérablement la productivité », écrivent les chercheurs dans leur rapport.
Si ces performances des modèles sont pour le moment modestes, cela pourrait évoluer d’ici quelques années, voire dans les mois à venir selon Foody. « Ça progresse vraiment très vite », a-t-il déclaré à TechCrunch. « Actuellement, on pourrait dire que c’est comme un stagiaire qui réussit une fois sur quatre, alors que l’an dernier, ce stagiaire réussissait cinq à dix pour cent du temps. Ce genre d’amélioration d’année en année peut avoir un impact considérable très rapidement », conclut-il.