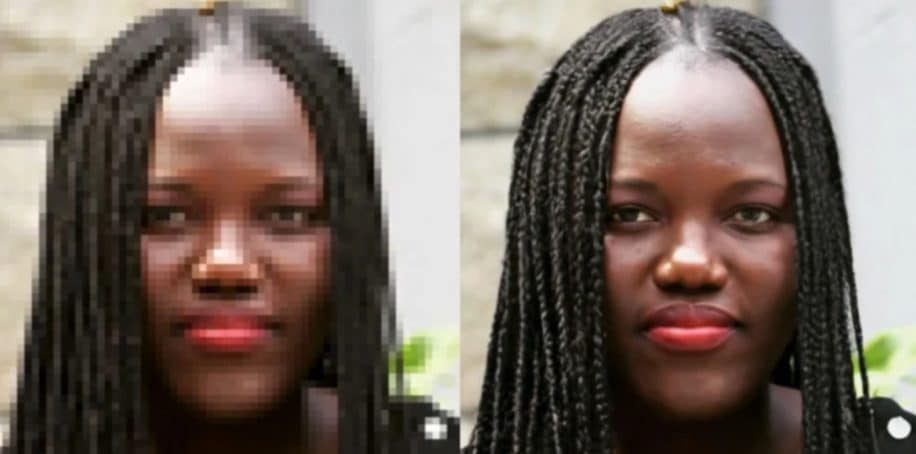
La technique est appelée « super-résolution » d’image. Il s’agit d’obtenir une image proche de la réalité à partir d’une image hyper pixelisée — typiquement, c’est un processus que l’on peut apercevoir dans de nombreux films ou séries policiers, lorsque les protagonistes zooment sur une photo afin de révéler, par exemple, la plaque d’immatriculation d’une voiture ou le visage de son conducteur, qui de base, sont non résolus. Les nouveaux outils d’intelligence artificielle développés par Google sont tout à fait capables de réaliser cela.
À noter que la technique est relativement complexe ; en effet, il s’agit ici d’ajouter à une image des détails que l’appareil photo n’a pas capturés au moment de la prise de vue. Les outils dont il est question ici parviennent à combler ces lacunes à partir d’autres images relativement similaires. Notez que le résultat n’est pas une copie conforme de la réalité, mais en est suffisamment proche pour que l’œil humain le considère comme tel.
Pour accomplir cette prouesse, Google a développé deux nouveaux outils : Super-Resolution via Repeated Refinement (SR3) et Cascaded Diffusion Models (CDM). Ce duo fournit des résultats époustouflants : lors d’un test d’observation impliquant une cinquantaine de volontaires, les images générées par ces nouveaux outils ont été confondues avec de véritables photos dans environ 50% des cas. « Avec SR3 et CDM, nous avons poussé les performances des modèles de diffusion à l’état de l’art », expliquent Jonathan Ho, chercheur scientifique et Chitwan Saharia, ingénieur logiciel, de la Brain Team de Google Research.
Une IA qui repose sur les modèles de diffusion
La super-résolution — soit la transformation d’une image basse résolution en une image haute résolution détaillée — a de nombreuses applications, qui peuvent aller de la restauration d’anciens portraits de famille à l’amélioration des systèmes d’imagerie médicale.
Les méthodes traditionnelles de synthèse d’images naturelles, notamment les images créées par les réseaux antagonistes génératifs (GAN), présentent quelques faiblesses lorsqu’il s’agit d’entraîner un modèle à synthétiser des échantillons de haute qualité à partir de données complexes et à haute résolution. C’est pourquoi les experts de Google Research se sont tournés vers ce que l’on appelle les modèles de diffusion, qui affichent une meilleure stabilité lors de la phase d’apprentissage et permettent de générer des échantillons d’images (et d’audio) de qualité.
Les modèles de diffusion fonctionnent en corrompant les données d’apprentissage : ils ajoutent du bruit gaussien progressivement, puis effacent lentement les détails des données jusqu’à ce qu’elles deviennent du bruit pur ; enfin, ils forment un réseau de neurones pour inverser ce processus de corruption. L’exécution de ce processus de corruption inversé synthétise les données à partir du bruit pur, en les débruitant progressivement jusqu’à ce qu’un échantillon « propre » soit produit.

C’est ainsi que fonctionne l’algorithme SR3 développé par Google : il ajoute du bruit ou de l’imprévisibilité à une image, puis inverse le processus — un peu à la manière dont un éditeur d’images tenterait d’affiner vos photos de vacances. Ainsi, à partir d’une série de calculs reposant sur une large base de données d’images, SR3 est capable d’imaginer à quoi ressemble une version haute résolution d’une photo de faible qualité. Le logiciel fournit des résultats de super-résolution impressionnants, tant pour des photos de visage que pour des images naturelles, lors de la mise à l’échelle à des résolutions de 4 à 8 fois celle de l’image basse résolution d’entrée.
Des modèles « en cascade » pour améliorer la qualité de l’agrandissement
Les chercheurs précisent en outre que ces modèles de super-résolution peuvent être utilisés en cascade pour augmenter le facteur d’échelle de super-résolution effectif — ce qui consiste, par exemple, à empiler un modèle de super-résolution de visage de 64×64 vers 256×256 et de 256×256 vers 1024×1024, afin d’effectuer une tâche de super-résolution de 64×64 vers 1024×1024.

Les Cascaded Diffusion Models (CDM) peuvent ainsi être vus comme des « pipelines » à travers lesquels les modèles de diffusion — y compris SR3 — peuvent être redirigés pour des mises à niveau de résolution d’image de haute qualité. Il prend en entrée les modèles d’amélioration et génère des images beaucoup plus grandes, avec une efficacité bien supérieure à celle des méthodes d’agrandissement actuelles. En plus d’inclure le modèle SR3 dans le pipeline, les chercheurs ont également introduit une nouvelle technique d’augmentation de données, appelée « augmentation de conditionnement », qui améliore encore les résultats de qualité d’échantillon de CDM.
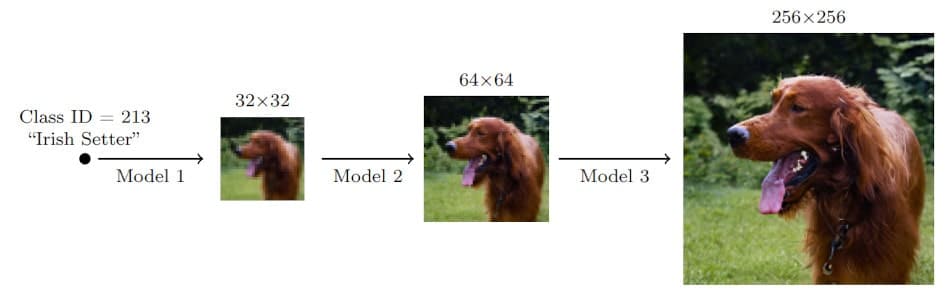
Ce nouveau moteur d’IA a notamment été testé sur ImageNet, une gigantesque base de données d’images d’entraînement couramment utilisée pour la recherche sur la reconnaissance visuelle d’objets. Les images de visages humains générées par SR3 ont été confondues avec de vraies photos environ 50% du temps ; un résultat vraiment impressionnant, sachant qu’un algorithme est considéré comme parfait lorsqu’il atteint un taux de confusion de 50%, selon les chercheurs.
Google envisage d’aller encore plus loin avec ses nouveaux moteurs d’intelligence artificielle et les technologies associées, non seulement en matière de mise à l’échelle d’images de visages et d’autres objets naturels, mais également dans d’autres domaines de la modélisation des probabilités. « Nous sommes ravis de tester davantage les limites des modèles de diffusion pour une grande variété de problèmes de modélisation générative », concluent les chercheurs.