
L’apprentissage automatique (machine learning) et l’informatique quantique ont en commun des schémas de fonctionnement similaires. Mais certains aspects de leurs fondements mathématiques sont également remarquablement identiques. Une équipe de chercheurs a exploité ce lien pour montrer comment les ordinateurs quantiques actuels peuvent, en principe, être utilisés pour apprendre à partir de données — en mappant des données dans l’espace dans lequel ne subsistent que des états quantiques.
L’une des premières choses que l’on apprend sur les ordinateurs quantiques est que ces machines sont extrêmement difficiles à simuler sur un ordinateur classique tel qu’un ordinateur de bureau. En d’autres termes, les ordinateurs classiques ne peuvent pas être utilisés pour obtenir les résultats d’un calcul quantique. La raison en est qu’il faut beaucoup de nombres pour décrire chaque étape interne du calcul.
Imaginez la procédure en plusieurs étapes que beaucoup de personnes apprennent à l’école pour diviser un grand nombre. S’il s’agissait d’un calcul quantique simulé sur un ordinateur classique, chaque étape intermédiaire pourrait facilement nécessiter plus de nombres pour le décrire qu’il n’y a d’atomes dans l’Univers observable.
L’état d’un système quantique, lorsqu’il est décrit par une collection de nombres, est appelé état quantique. Et si un état quantique est associé à de nombreuses valeurs, il est décrit comme évoluant dans un grand espace. Pour certains ordinateurs quantiques basés sur des variables continues, de tels espaces peuvent même être infiniment grands.
Des espaces de données trop importants pour l’informatique classique
L’apprentissage automatique, par comparaison, analyse des données qui résident dans des espaces beaucoup plus petits, c’est-à-dire que les données sont décrites avec beaucoup moins de valeurs. Par exemple, une photographie contenant un million de pixels n’enregistre que trois millions de nombres pour décrire la quantité de rouge, de vert et de bleu dans chaque pixel.
Une tâche essentielle de l’apprentissage automatique pourrait consister à deviner le contenu de l’image ou à produire des images similaires. Cependant, une théorie bien établie en apprentissage automatique, appelée méthode du noyau, traite les données de manière similaire à celle utilisée par la théorie quantique.
En résumé, les méthodes du noyau effectuent un apprentissage automatique en définissant quels points de données sont similaires et lesquels ne le sont pas. Mathématiquement, la similarité est une distance dans l’espace de données, c’est-à-dire une distance entre les représentations des points de données sous forme de nombres.
Des images similaires sont supposées avoir un contenu similaire, et les distances entre les points de données peuvent être cruciales dans l’apprentissage automatique. Mais définir des similitudes n’est pas aussi simple que cela en a l’air. Par exemple, quelle est la distance dans l’espace de données entre deux images, si elle est calculée sur la base de la quantité de rouge dans chaque image ?
La théorie des noyaux a montré que de nombreuses définitions de la similarité dans l’espace de données sont mathématiquement équivalentes à une simple mesure de la similarité dans un espace beaucoup plus grand, voire infiniment grand. Par conséquent, chaque fois que deux images sont comparées, les images sont implicitement mappées à une représentation dans un espace immense, et une simple similarité est calculée.
Un apprentissage automatique au sein d’espaces quantiques rendu possible grâce à l’informatique quantique
Aucun ordinateur ordinaire ne peut calculer explicitement cette grande représentation. Mais peut-être qu’un ordinateur quantique le peut. Les ordinateurs quantiques effectuant des calculs dans des espaces extrêmement grands, que se passe-t-il si les données sont mappées dans l’espace au sein desquels évoluent des états quantiques ?
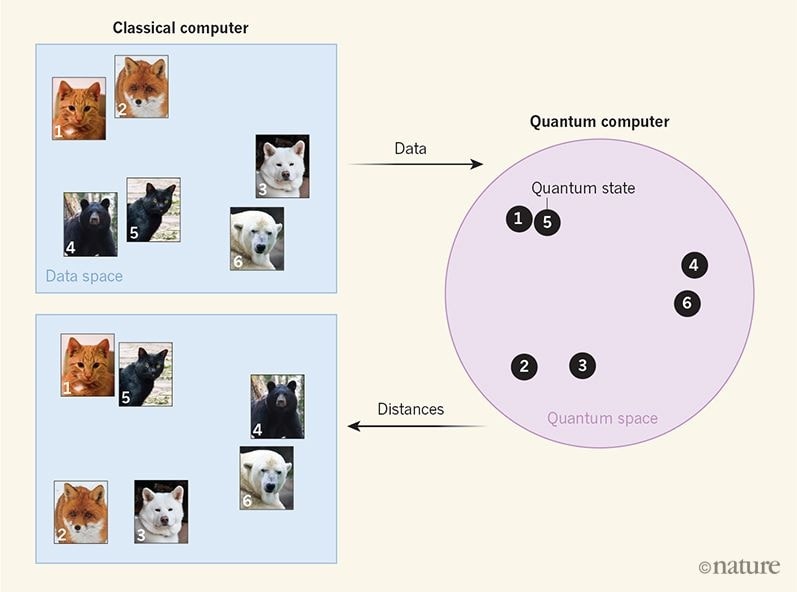
La première stratégie n’utilise que très peu l’ordinateur quantique, en tant que simple ajout matériel à un système d’apprentissage automatique classique : le dispositif quantique renvoie des similitudes lorsque deux points de données sont donnés. La deuxième stratégie effectue l’apprentissage effectif sur l’ordinateur quantique, avec l’aide de la méthode classique.
Des chercheurs ont implémenté les deux stratégies dans une expérience de validation de principe sur un ordinateur quantique réel : l’une des puces quantiques d’IBM. Quiconque a expérimenté l’informatique quantique dans le cloud, sait qu’il est notoirement difficile de collecter des données significatives à partir de ces appareils, en raison des niveaux élevés de bruit expérimental dans le calcul.

Sur le même sujet : La combinaison de qubits résout les problèmes majeurs de l’informatique quantique
L’espace quantique n’a que quatre dimensions, car la configuration utilise deux bits quantiques (qubits) de la plus petite puce d’IBM, à cinq qubits — à un moment où le service cloud IBM offre déjà l’accès à un périphérique à 20 qubits. L’ensemble de données est également conçu à la main de manière à pouvoir être analysé facilement dans cet espace à quatre dimensions.
Néanmoins, le travail de Havlíček et de ses collègues, publié dans la revue Nature, présente une démonstration de principe intrigante d’une manière potentiellement révolutionnaire d’utiliser des ordinateurs quantiques pour l’apprentissage automatique. Après de nombreuses études proposant diverses tentatives pour transformer les réseaux de neurones artificiels beaucoup plus populaires en informatique quantique, les méthodes à noyau fournissent un pont naturel entre l’apprentissage automatique et la théorie quantique.
Il reste à voir si la manière dont les chercheurs ont représenté des données dans un espace quantique est réellement utile pour des applications d’apprentissage automatique dans le monde réel. Autrement dit, on ne sait pas si l’approche est associée à une mesure significative de similarité ; par exemple, en classant les images d’animaux, savoir si elle place les images de chat à proximité des images de chats, mais pas les images de chiens.
De plus, il n’est pas clair s’il existe d’autres stratégies qui fonctionneraient mieux. Et ces techniques suffiraient-elles à surpasser près de 30 ans de méthodes classiques ? Si tel est le cas, la recherche ultime d’une « application idéale » pour les ordinateurs quantiques serait terminée. Mais la réponse à cette question est probablement plus compliquée.