
Des chercheurs de l’Université de Stanford ont mis au point un nouveau modèle informatique permettant de trouver un compromis entre reprise de l’activité (entre autres économique) et contrôle du nombre d’infections COVID-19. Ainsi, sur sa base, il serait possible de prévoir des stratégies de relance précises, qui seraient donc beaucoup plus sûres et efficaces.
Le monde n’attend désormais qu’une chose, pouvoir se libérer une fois pour toutes du SARS-CoV-2, le coronavirus responsable de la COVID-19. Et pour cela, les vaccins et les traitements en développement sont la source principale de l’espoir qui nous motive. Mais comme déjà annoncé dans de précédents articles, alors que les premiers vaccins ne seront disponibles qu’en fin d’année ou début 2021 en quantités limitées, il est indispensable de réfléchir à des plans de relance « qui font avec ».
En effet, même si les vaccins sont réellement si efficaces que récemment annoncé, le temps qu’une proportion suffisante de la population se fasse vacciner, le virus circulera sans problème en tout cas jusqu’en 2022. Il est donc crucial de mettre au point et d’appliquer des plans de relance tenant compte de la situation actuelle, pour une économie mondiale déjà à bout de souffle… La pandémie de COVID-19 a déjà radicalement changé les habitudes de mobilité humaines, nécessitant des modèles épidémiologiques qui saisissent les effets des changements de mobilité sur la propagation du virus. C’est notamment en considérant cela que les chercheurs de l’Université de Stanford ont pu mettre au point un nouveau modèle précis.
Un modèle basé sur les déplacements et habitudes de 98 millions de personnes
Dans leur document, publié dans la revue Nature, les scientifiques présentent un modèle SEIR de métapopulation (un modèle mathématique de propagation d’une maladie infectieuse) qui intègre des réseaux de mobilité dynamiques pour simuler la propagation du SARS-CoV-2. Pour cela, ils se sont basés sur dix des plus grandes zones statistiques métropolitaines des États-Unis.
Ils ont notamment utilisé des données issues des téléphones portables et des réseaux de mobilité de 98 millions de personnes, permettant de cartographier les déplacements horaires depuis les quartiers (qu’ils appellent « groupes d’îlots de recensement », notés CBG) jusqu’aux points d’intérêt (POI) tels que les restaurants, les centres commerciaux ou encore les établissements religieux. Ainsi, le modèle a relié 57’000 CBG à 553’000 POI, avec 5,4 milliards de tranches horaires.

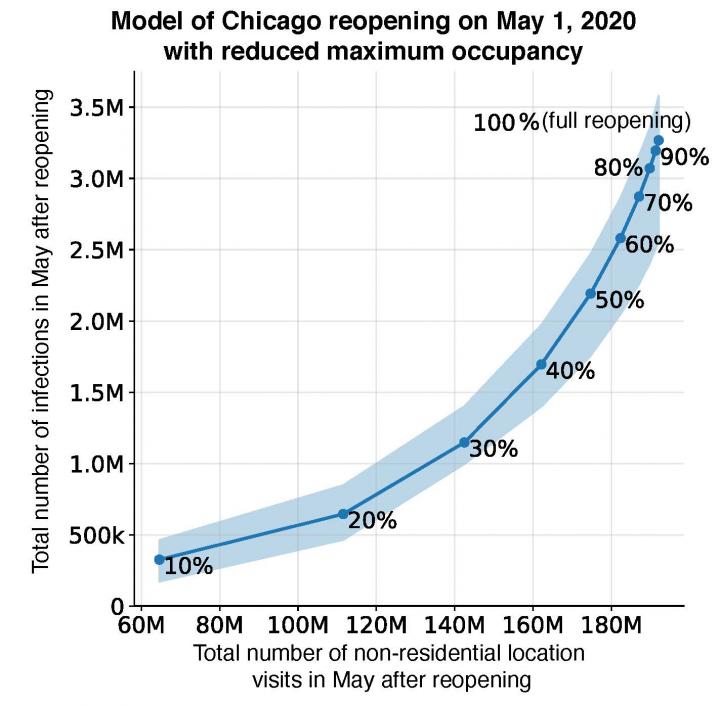 Le nouveau modèle informatique prédit le compromis entre l’infection par le SARS-CoV-2 et l’activité (ici à Chicago). Selon le schéma, les infections COVID-19 augmenteront à mesure que le nombre de visites dans les entreprises et les lieux publics approche des niveaux pré-pandémiques. Cependant, restreindre l’occupation maximale peut permettre de trouver un équilibre efficace : par exemple, un plafond d’occupation de 20% permettrait encore 60% des visites pré-pandémiques, tout en risquant seulement 18% des infections qui se produiraient si les lieux publics rouvraient complètement. Crédits : Serina Yongchen Chang
Le nouveau modèle informatique prédit le compromis entre l’infection par le SARS-CoV-2 et l’activité (ici à Chicago). Selon le schéma, les infections COVID-19 augmenteront à mesure que le nombre de visites dans les entreprises et les lieux publics approche des niveaux pré-pandémiques. Cependant, restreindre l’occupation maximale peut permettre de trouver un équilibre efficace : par exemple, un plafond d’occupation de 20% permettrait encore 60% des visites pré-pandémiques, tout en risquant seulement 18% des infections qui se produiraient si les lieux publics rouvraient complètement. Crédits : Serina Yongchen ChangLes chercheurs montrent qu’en intégrant ces réseaux, un modèle SEIR relativement simple peut s’adapter exactement à la trajectoire du cas réel, malgré des changements substantiels dans le comportement de la population au fil du temps. Cela permet d’atteindre une précision de prédiction impressionnante. Ainsi, leur modèle prédit qu’une petite minorité de POI « super-propagateurs » représente une grande majorité des infections, et qu’il est plus efficace de limiter l’occupation maximale de chaque POI que de réduire uniformément la mobilité.


Le modèle prédit également à juste titre des taux d’infection plus élevés parmi les groupes ethniques et socio-économiques défavorisés, uniquement en raison des différences de mobilité. « Nous constatons que les groupes défavorisés n’ont pas été en mesure de réduire la mobilité aussi fortement, et que les points d’intérêt qu’ils visitent sont plus fréquentés et donc plus risqués », écrivent les chercheurs dans le document. En saisissant qui est infecté à quels endroits, les résultats soutiennent des analyses détaillées qui peuvent informer et permettre des réponses politiques plus efficaces et plus équitables pour lutter contre la pandémie.