
Il y a quelques jours, Microsoft annonçait le remplacement de dizaines de journalistes par une intelligence artificielle. Sa tâche ? Sélectionner et hiérarchiser des sujets pour alimenter les pages d’actualités du navigateur Edge et du site de MSN. Problème : à peine mise en place, cette IA confond les photos de deux jeunes femmes d’origine afro-britannique…
L’un des principaux arguments en défaveur du développement de l’intelligence artificielle est la crainte que cette technologie finisse par priver des milliers de personnes de leur emploi. Cette crainte est devenue bien réelle du côté de Redmond, dans la banlieue de Seattle, où siège l’entreprise de Bill Gates. Près de 80 journalistes américains et britanniques se sont retrouvés sur le carreau, remplacés par des programmes…
Des IA loin d’être irréprochables
À noter que ces ex-employés de Microsoft n’étaient pas chargés de l’écriture ; leur rôle était d’effectuer une sélection parmi les articles produits par des tiers, afin d’alimenter les pages d’actualités de MSN et du navigateur Edge. Un travail de curation et de hiérarchisation de l’information, pour élaborer une revue de presse quotidienne à destination des usagers. L’ajout de titres et d’éventuelles modifications minimes étaient également de leur ressort. L’essentiel étant de faire en sorte que les utilisateurs ne soient jamais exposés à des contenus violents ou inappropriés.
Les algorithmes mis en place par Microsoft font-ils le poids ? L’exercice n’est pas si simple, même pour des agents intelligents. Google Actualités repose déjà sur des IA pour ses activités de curation, de même que YouTube et Facebook. De temps à autre, des informations provenant de sources douteuses, voire des fake news, apparaissent pourtant sur l’une ou l’autre plateforme.
L’application Apple News a quant à elle subi plusieurs fois les affres des ratés de la hiérarchisation : fin 2018, l’histoire anodine d’un salon de coiffure breton s’était retrouvée en tête des actualités, devant l’affaire Carlos Ghosn ! Peu de temps auparavant, un fait divers rapporté par un journal régional s’était lui aussi retrouvé sous les feux de la rampe. Par la suite, la firme de Palo Alto a préféré abandonner le recours à l’IA pour gérer son widget d’information.
Quid de la nouvelle IA de Microsoft ? Ses premiers pas sont maladroits… L’algorithme a récemment illustré un article avec la mauvaise photo : le programme a confondu deux femmes du groupe de pop britannique Little Mix ; l’article était au sujet de Jade Thirlwall, tandis que la photo correspondait à Leigh-Anne Pinnock. Et il se trouve que toutes deux sont des femmes de couleur. La goutte qui fait déborder le vase : dans cet article, la chanteuse relate à quel point elle a souffert de racisme dans son enfance, alors qu’elle était l’une des trois seules personnes de couleur dans son école catholique. En plein mouvement Black Lives Matter, l’erreur fait du bruit…

 L’intelligence artificielle de Microsoft a confondu ces deux membres du groupe Little Mix, Jade Thirlwall (à gauche) et Leigh-Anne Pinnock (à droite). Crédits : Wikimedia Commons.
L’intelligence artificielle de Microsoft a confondu ces deux membres du groupe Little Mix, Jade Thirlwall (à gauche) et Leigh-Anne Pinnock (à droite). Crédits : Wikimedia Commons.La réaction de la chanteuse sur Instagram est immédiate : « Cette merde nous arrive à @leighannepinnock [et moi] TOUT LE TEMPS […]. Cela m’offense que vous ne puissiez pas différencier les deux femmes de couleur des quatre membres d’un groupe… FAITES MIEUX ! ». L’image a bien entendu été immédiatement remplacée une fois l’erreur remontée, mais la société n’a pas commenté le problème sous-jacent lié à l’apparent parti pris racial de son IA. Les employés de MSN ont néanmoins été chargés de retirer de la revue de presse tout article gênant traitant de cette affaire…
Des erreurs dues aux préjugés de l’Homme…
The Guardian rapporte qu’un membre du personnel a déclaré que Microsoft était profondément préoccupée par les dommages causés à la réputation de son IA : « Avec toutes les manifestations contre le racisme en ce moment, ce n’est pas le moment de faire des erreurs ». Mais ces erreurs, à quoi, ou à qui sont-elles dues exactement ?
Ce n’est pas la première fois que des algorithmes d’IA sont soupçonnés de faire preuve de préjugé racial. Il y a deux ans, un article du NewScientist rapportait déjà que ces programmes étaient susceptibles d’amplifier les préjugés sexistes et racistes de la société. N’oublions pas que ces agents intelligents sont programmés et entraînés par des humains. Les données d’entrée sont sélectionnées et triées par des humains et sont donc le reflet direct de leurs convictions.
Ainsi, ProPublica – un organisme américain à but non lucratif, spécialisé dans le journalisme d’investigation – révélait en 2016 que COMPAS affichait clairement un parti pris racial. COMPAS ? C’est un algorithme utilisé aux États-Unis pour prédire la probabilité d’une récidive criminelle et ainsi, déterminer la peine de l’accusé en conséquence. Selon les analyses, le système prévoit que les accusés noirs présentent un risque de récidive plus élevé que les accusés blancs.
Même constat pour PredPol, un algorithme conçu pour prédire quand et où les crimes auront lieu, utilisé dans plusieurs États américains. En 2016, le Human Rights Data Analysis Group a constaté que le logiciel pouvait conduire la police à cibler injustement certains quartiers ; une simulation a envoyé à plusieurs reprises les agents dans des quartiers comptant une forte proportion de personnes issues de minorités raciales, quel que soit le véritable taux de criminalité dans ces régions.
Autre exemple de discrimination : en 2018, l’étude de trois algorithmes utilisés dans la reconnaissance faciale – créés par Microsoft, IBM et Megvii – a révélé qu’ils identifiaient correctement le sexe d’une personne à partir d’une photographie dans 99% des cas, mais seulement lorsqu’il s’agissait d’hommes blancs. Pour les femmes à la peau foncée, la précision tombait à 35% !
L’an dernier, Maarten Sap et ses collègues de l’Université de Washington ont découvert que les IA entraînées à reconnaître les discours de haine en ligne étaient jusqu’à deux fois plus susceptibles d’identifier les tweets comme offensants lorsqu’ils étaient rédigés en anglais afro-américain – un dialecte parlé principalement par la communauté noire aux États-Unis – ou par des personnes identifiées comme étant d’origine afro-américaine. L’outil Perspective, créé par Google et Jigsaw pour détecter les abus et modérer les discussions en ligne, n’échappe pas à la règle.

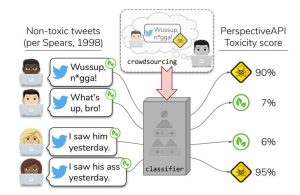 Phrases rédigées en anglais afro-américain, leurs équivalents en anglais, et leurs scores de « toxicité » attribués par l’outil Perspective conçu par Jigsaw/Alphabet. Crédits : Maarten Sap et al.
Phrases rédigées en anglais afro-américain, leurs équivalents en anglais, et leurs scores de « toxicité » attribués par l’outil Perspective conçu par Jigsaw/Alphabet. Crédits : Maarten Sap et al.Mais ces IA censées détecter des incitations à la haine ont été formées à partir de données textuelles, manuellement sélectionnées et triées par des humains ! En étudiant de près un ensemble typique de ces données, Sap et son équipe ont relevé une corrélation significative entre les tweets écrits en anglais afro-américain et la probabilité qu’ils soient étiquetés comme « insultants » par un humain. Puis, après avoir formé deux IA à partir de cet ensemble de tweets, ils ont constaté que la moins performante avait classé 46% de tweets rédigés en anglais afro-américain comme « insultants », alors qu’ils étaient complètement inoffensifs.
Sur le même sujet : Cette IA peut définir la personnalité d’un individu en fonction de ses selfies
Les conséquences ? « L’utilisation d’IA biaisées par les principales plateformes pourrait avoir des conséquences négatives, telles que la suppression des voix des minorités », explique Sap. Au final, difficile de considérer que les algorithmes chargés de modérer les contenus sont complètement fiables. « Parce que les humains sont intrinsèquement biaisés, nous devons supposer que tous les algorithmes sont biaisés », explique Matthew Williams, directeur du HateLab à l’Université de Cardiff.