
Les algorithmes de machine-training, consistant à former des systèmes d’intelligence artificielle à reconnaître des images, reposent majoritairement sur des bases d’images pré-construites par les humains. Or, ces bases (comme ImageNet ou Places) sont difficiles à mettre en place, demandent énormément de temps et peuvent contenir d’importants biais d’étiquetage. Des chercheurs japonais ont récemment montré qu’au lieu d’entraîner l’IA sur ces bases de données standard, il était possible d’utiliser des fractales. Dénuées de biais et virtuellement illimitées, les fractales pourraient constituer un substitut d’entraînement efficace pour la reconnaissance d’objets.
La plupart des systèmes de reconnaissance d’images sont formés à l’aide de grandes bases de données contenant des millions de photos d’objets du quotidien. Avec une exposition répétée, les IA apprennent à distinguer un type d’objet d’un autre. Des chercheurs japonais ont montré que les IA peuvent commencer à apprendre à reconnaître des objets du quotidien en étant plutôt entraînées sur des fractales générées par ordinateur.
La génération automatique de données d’entraînement est une tendance active en apprentissage automatique. Et l’utilisation d’une quantité infinie d’images synthétiques plutôt que de photos extraites d’Internet évite les problèmes avec les ensembles de données artisanaux existants.
Les problèmes associés aux bases d’images standards
Le pré-entraînement est une phase durant laquelle une IA apprend certaines compétences de base avant d’être formée sur des données plus spécialisées. Les modèles pré-entraînés permettent à plus de personnes d’utiliser une IA puissante. Au lieu d’avoir à former un modèle à partir de zéro, les professionnels peuvent adapter un modèle existant à leurs besoins.
Par exemple, un système de diagnostic des scans médicaux peut d’abord apprendre à identifier les caractéristiques visuelles de base, telles que la forme et le contour, en étant pré-formé sur une base de données d’objets du quotidien, comme ImageNet, qui contient plus de 14 millions de photos. Ensuite, il sera affiné sur une base de données plus petite d’images médicales jusqu’à ce qu’il reconnaisse des signes subtils de maladie.
Le problème, c’est que l’assemblage manuel d’un ensemble de données comme ImageNet prend beaucoup de temps et d’efforts. Les images sont généralement étiquetées par des travailleurs en ligne mal payés. Les ensembles de données peuvent également contenir des étiquettes sexistes ou racistes qui peuvent biaiser un modèle de manière cachée, ainsi que des images de personnes qui ont été incluses sans leur consentement. Il existe des preuves que ces préjugés peuvent s’infiltrer même dans le pré-entraînement.
Les formes naturelles issues des fractales
Les fractales peuvent être trouvées partout, dans les arbres et les fleurs, en passant par les nuages et les vagues. Cela a amené l’équipe de l’Institut national japonais des sciences et technologies industrielles avancées (AIST), de l’Institut de technologie de Tokyo et de l’Université de Tokyo Denki, à se demander si ces modèles pourraient être utilisés pour enseigner à un système automatisé les bases de la reconnaissance d’images, au lieu d’utiliser des photos d’objets réels.

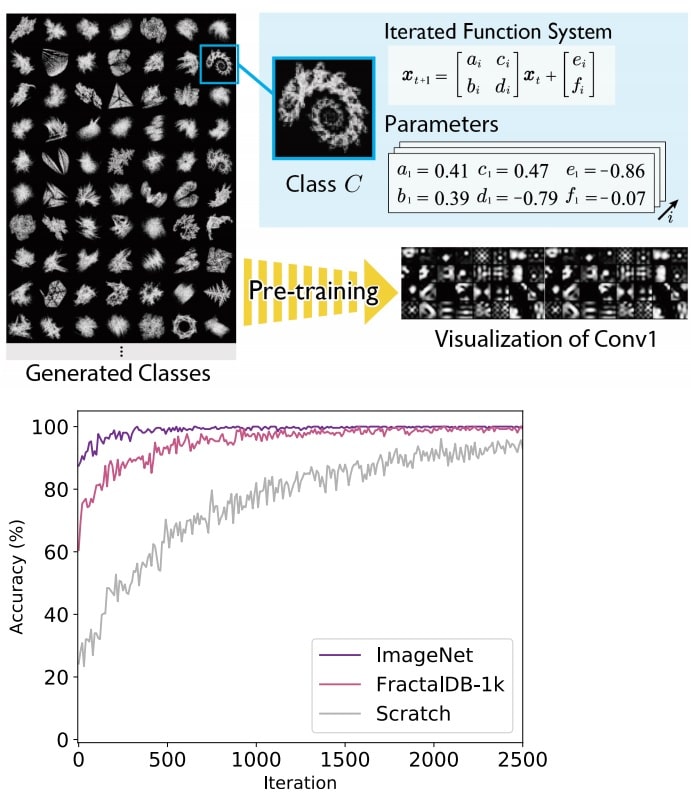 Haut : une banque de fractales est générée, chaque fractale étant étiquetée mathématiquement par l’algorithme. Bas : graphique comparant l’efficacité d’entraînement entre la base standard ImageNet (violet), FractalDB (rose) et à partir de zéro (gris). © Hirokatsu Kataoka et al. 2021
Haut : une banque de fractales est générée, chaque fractale étant étiquetée mathématiquement par l’algorithme. Bas : graphique comparant l’efficacité d’entraînement entre la base standard ImageNet (violet), FractalDB (rose) et à partir de zéro (gris). © Hirokatsu Kataoka et al. 2021Les chercheurs ont créé FractalDB, un nombre infini de fractales générées par ordinateur. Certains ressemblent à des feuilles, d’autres ressemblent à des flocons de neige ou à des coquilles d’escargot. Chaque groupe de modèles similaires a reçu automatiquement une étiquette. Ils ont ensuite utilisé FractalDB pour pré-entraîner un réseau de neurones convolutifs, un type de modèle d’apprentissage profond couramment utilisé dans les systèmes de reconnaissance d’images, avant de terminer sa formation avec un ensemble d’images réelles.


Ils ont constaté qu’il fonctionnait presque aussi bien que les modèles formés sur des ensembles de données de pointe, y compris ImageNet et Places, qui contient 2.5 millions d’images de scènes extérieures. Est-ce que ça marche ? Anh Nguyen de l’université d’Auburn en Alabama, qui n’était pas impliquée dans l’étude, n’est pas convaincue que FractalDB soit à la hauteur d’ImageNet.
Vers un remplacement progressif des bases d’images ?
Nguyen a étudié comment des motifs abstraits peuvent confondre les systèmes de reconnaissance d’images. « Il existe un lien entre ce travail et des exemples qui trompent les machines », déclare-t-il. Il aimerait explorer plus en détail comment cette nouvelle approche fonctionne. Mais les chercheurs japonais pensent qu’avec des ajustements apportés à ce système, des ensembles de données générés par ordinateur comme FractalDB pourraient remplacer ceux existants.
Ils ont également essayé d’entraîner leur IA en utilisant d’autres images abstraites, y compris celles produites à l’aide du bruit Perlin, qui crée des motifs mouchetés, et des courbes de Bézier, un type de courbe utilisé en infographie. Mais les fractales ont donné les meilleurs résultats.