
Et si notre voix ne nous appartenait plus totalement ? Microsoft vient de publier les résultats de recherches sur une nouvelle intelligence artificielle nommée VALL-E. Celle-ci serait capable de reproduire une voix très rapidement (en 3 secondes) à partir d’extraits audio.
3 secondes… C’est le temps d’enregistrement qu’il faut à cette nouvelle IA créée par des ingénieurs de Microsoft pour reproduire la voix de quelqu’un. Les chercheurs à l’origine de ce projet ont publié de premiers résultats sur le serveur de préimpression arXiv. Cela signifie qu’elles attendent encore d’être validées par leurs pairs. Ils ont toutefois publié des exemples concrets des résultats obtenus sous forme de fichiers audio. La précision atteinte par certains de ces échantillons a de quoi faire froid dans le dos.
Le fonctionnement est relativement simple : une voix enregistrée est fournie à VALL-E, sous la forme d’un fichier audio de trois secondes minimum. Un autre texte est ensuite rentré. VALL-E « lit » ce texte en utilisant les intonations issues de l’enregistrement fourni. Microsoft n’est pas la première entreprise à se pencher sur la question. Il n’y a pas si longtemps, Amazon avait fait une publicité discutable à l’une de ses IA capable de reproduire la voix de personnes décédées pour « faire durer leur mémoire ». La performance était déjà assez glaçante : elle promettait toutefois des résultats pour un enregistrement de « moins d’une minute ». Loin des trois secondes revendiquées ici par Microsoft.
VALL-E présente de surcroît des capacités particulières en matière d’environnement. Les chercheurs ont travaillé sur la possibilité de reproduire du bruit lié à l’environnement de la personne enregistrée. L’IA se révèle même capable d’identifier et de reproduire des intonations liées à une émotion particulière : joie, colère, dégoût, fatigue… Tous les résultats présentés ne sont pas parfaitement convaincants. Cependant, certains sont quasiment impossibles à distinguer de la voix humaine originale.
Ci-dessous, un exemple avec la phrase « We have to reduce the number of plastic bags. » :
Enregistrement audio :
Reproduction par VALL-E :
Comment ça marche ?
Les recherches ayant mené à cet outil appartiennent au domaine de l’apprentissage automatique. Pour parvenir à un modèle d’apprentissage efficace, il faut « nourrir » le programme, appelé plus communément IA ou « intelligence artificielle », avec des données sources qui lui permettent de déduire des connexions logiques, et donc « d’apprendre ». Dans le cas de VALL-E, les chercheurs l’ont alimentée grâce à une base de données fournie par Meta : Libri Light. Cette base de données contient « 60 000 heures de discours non étiquetés à partir de livres audio en anglais et un petit ensemble de données étiquetées (10h, 1h et 10 min) ainsi que des métriques, des modèles de base entraînables et des modèles pré-entraînés qui utilisent ces ensembles de données », décrit Meta.

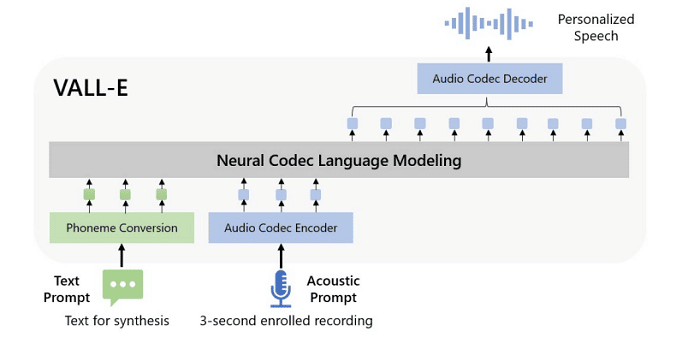
Suffisant, visiblement, pour obtenir de premiers résultats convaincants. Comme on le voit sur le schéma ci-dessous, l’audio et le texte sont injectés simultanément dans le système. L’audio est analysé, et le texte décomposé en phonèmes : c’est-à-dire la plus petite unité de langage que l’on peut prononcer. Grâce à un programme très spécifique, VALL-E est alors capable de synthétiser ces informations pour créer la voix qui lit le texte stipulé.
Évidemment, il n’est pas très compliqué d’imaginer des scénarios d’usage peu réjouissants à partir de cette technologie. D’ailleurs, les scientifiques en font eux-mêmes mention dans leurs travaux : « Puisque VALL-E pourrait synthétiser la parole qui maintient l’identité du locuteur, il peut comporter des risques en cas d’utilisation abusive du modèle, comme l’usurpation d’identité vocale ou l’usurpation de l’identité d’un locuteur spécifique ». La solution identifiée serait pour eux de construire un système qui permettrait de détecter l’usage de leur technologie. Une solution qui suscite quelques remarques ironiques : « Ce qui peut amener une ou deux personnes à se demander : ‘Pourquoi avez-vous fait cela, alors ?’ Assez souvent, dans le domaine de la technologie, la réponse est : ‘Parce que nous le pouvions’ », ironise ainsi un journaliste de ZDNet dans un article.