
L’intelligence artificielle, dans ses plus grandes et ambitieuses applications, nécessite une puissance de calcul conséquente, d’où la nécessité de recourir à de puissants ordinateurs mis en réseau pour en augmenter la capacité totale. Dans une prouesse sans égal, le géant Microsoft et le célèbre fabricant de puces et cartes graphiques Nvidia ont créé une vaste intelligence artificielle capable d’imiter le langage humain de manière plus convaincante que jamais.
Dans leur développement commun, les deux géants de l’informatique se sont rapidement heurtés au premier problème évoqué : plus un projet s’appuyant sur l’intelligence artificielle est ambitieux, plus il sera limité par l’infrastructure technologique plutôt que par la théorie. À cela s’ajoutent le coût et le temps nécessaires à la mise en place d’un système d’une telle envergure. Autrement dit, la possibilité de faire évoluer de telles IA est à ce jour fortement limitée par ces obstacles.
Le projet consistait à développer un réseau neuronal gigantesque, comptant plus de 530 milliards de paramètres ! Baptisé Megatron-Turing Natural Language Generation (MT-NLG), ce système compte ainsi plus du triple de paramètres du réseau neuronal révolutionnaire GPT-3 d’OpenAI, considéré jusqu’à présent comme le plus riche à ce niveau-là.
Un projet malheureusement trop énergivore, coûteux et chronophage
Puisque l’on parle de coûts et de temps, précisons d’entrée que ce développement a nécessité plus d’un mois de travail sur un superordinateur doté de près de 4500 cartes graphiques très puissantes (et donc coûteuses), qui sont généralement utilisées pour exécuter des réseaux neuronaux haut de gamme.
Lorsqu’OpenAI a publié GPT-3 l’année dernière, il a surpris les chercheurs par sa capacité à générer des flux de texte fluides. Il utilisait pour cela 175 milliards de paramètres — des emplacements de données alloués au sein d’un ordinateur qui reproduisent les synapses entre les neurones du cerveau — ainsi que de grandes quantités de textes accessibles publiquement à partir desquels il a appris des modèles de langage. Depuis, Microsoft a acquis une licence exclusive d’utilisation de GPT-3.
Mais l’entreprise voulait faire mieux et plus grand. Lorsque Microsoft et Nvidia ont testé MT-NLG sur une série de tâches linguistiques, telles que la prédiction du mot qui suit une section de texte et l’extraction d’informations logiques du texte, ils ont constaté qu’il était légèrement meilleur que GPT-3 à compléter des phrases avec précision et à imiter le raisonnement de bon sens. Sur un point de référence où l’IA doit prédire le dernier mot d’une phrase, GPT-3 a obtenu une précision de 86,4%, tandis que la nouvelle IA a atteint 87,2%.
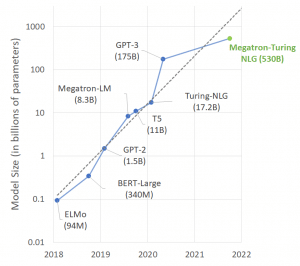
Cette infime différence serait simplement due à la quantité plus importante de neurones (paramètres). Et c’est loin d’être bon marché… « L’entraînement d’un de ces modèles coûte effectivement des millions de dollars car les ressources informatiques nécessaires à cet effet augmentent rapidement avec la taille du modèle », explique Bryan Catanzaro de Nvidia.
MT-NLG a été entraîné à l’aide du superordinateur Selene de Nvidia, composé de 560 serveurs haute performance, chacun équipé de huit unités de traitement graphique (GPU) Tensor Core A100 de 80 Gb. Chacune de ces 4480 cartes graphiques, initialement conçues pour les jeux vidéo mais aussi extrêmement performantes pour traiter de grandes quantités de données tout en formant des IA, coûte actuellement des milliers d’euros dans le commerce. Bien que la totalité de la puissance de l’ordinateur n’ait pas été utilisée uniquement par cette équipe de recherche, il a fallu plus d’un mois pour former l’IA.
Même l’exécution du réseau neuronal une fois qu’il est formé nécessite tout de même 40 de ces GPU, et chaque requête prend entre 1 et 2 secondes à traiter. Cette extension constante de l’échelle signifie que la recherche sur l’IA est désormais, dans une certaine mesure, un problème d’ingénierie consistant à diviser efficacement le problème et à le répartir sur de grandes quantités de matériel.
Quand l’échelle touche le plafond des coûts…
Catanzaro affirme que l’échelle a été la force dominante dans l’apprentissage automatique pendant des décennies. « Il est tout à fait vrai que de meilleurs algorithmes aident, et il est 100% vrai que plus de données et de meilleures données aident absolument, mais je pense que l’échelle de calcul a vraiment été la force motrice de beaucoup de progrès dans ce domaine », dit-il.

Bien entendu, de nombreux chercheurs hésitent à se fier à la seule mise à l’échelle, car ils souhaitent une solution plus élégante, surtout que les mesures de référence reflètent de petites améliorations. Cependant, d’autres chercheurs pensent qu’il y a des progrès significatifs dans la façon dont les IA raisonnent et extraient des informations nuancées simplement en augmentant l’échelle des systèmes.
Samuel Bowman, de l’université de New York, estime que les critères actuels d’évaluation de la qualité des IA de traitement du langage arrivent à la fin de leur vie utile et que les chercheurs sont à la recherche de nouvelles mesures pouvant être utilisées pour évaluer la qualité du langage et même du raisonnement. Ces mêmes chercheurs attendent aussi « nerveusement » de savoir si l’échelle peut continuer à apporter des améliorations ou si elle va atteindre un plafond, dit-il, car le coût de la recherche dans ce domaine augmente rapidement.
« Il s’agit sans aucun doute de certains des projets les plus coûteux dans ce domaine, mais le fait qu’ils soient trop coûteux dépend de la façon dont on perçoit leur potentiel », explique-t-il. « Si vous les voyez comme des étapes vers une forme d’IA assez largement utile, et que vous considérez cela comme souhaitable, alors il est facile d’imaginer justifier des budgets beaucoup plus importants ».
« La qualité et les résultats que nous avons obtenus aujourd’hui constituent un grand pas en avant vers la réalisation de toutes les promesses de l’IA en langage naturel. Les innovations de DeepSpeed et de Megatron-LM profiteront au développement de modèles d’IA actuels et futurs et rendront l’entraînement de grands modèles d’IA moins coûteux et plus rapide », écrivent les chercheurs dans le communiqué de Nvidia. Les nouveaux modèles d’IA permis par une telle infrastructure pourraient donc également contribuer à les rendre plus rapides et moins énergivores, ce qui par conséquent permettrait d’en réduire la taille.