
De plus en plus de systèmes robotisés sont capables d’apporter leur aide aux humains dans des tâches diverses et variées. Pourtant, il n’est pas toujours aisé de déterminer avec précision quand le robot doit intervenir dans un processus humain sans le gêner. Jason R. Wilson, Phyo Thuta Aung et Isabelle Boucher se sont penchés de près sur la question et ont développé un système qui permet aux robots de détecter automatiquement si une personne a besoin d’aide ou non dans l’accomplissement d’une tâche.
Cette équipe de chercheurs du Franklin & Marshall College Lancaster, en Pennsylvanie, a en effet remarqué qu’il est encore difficile de faire intervenir le robot dans les tâches humaines de façon pertinente. Très souvent, les avancées se consacrent à déterminer « comment » le robot devrait aider l’utilisateur, mais oublient de se focaliser sur le moment où l’intervention est requise. Pour les scientifiques, ce critère est pourtant clef au sein de l’expérience utilisateur associée à un robot.
Forts de ce constat, ils ont donc développé un système qui permet aux robots de détecter automatiquement si une personne a besoin d’aide ou non dans l’accomplissement d’une tâche. Appliqué à divers types de robots, ce système introduirait une dimension d’autonomie. Il leur permettra d’être en capacité de « décider eux-mêmes » d’intervenir, en se basant sur la situation en temps réel, qu’il s’agisse de monter un meuble Ikea ou de cuisiner des cookies.
L’idée est simple, mais le défi était de taille. Il fallait en effet faire en sorte que le robot n’intervienne pas trop peu, ce qui a tendance à diminuer la confiance qu’on lui accorde, mais pas non plus trop. Dans ce dernier cas, cela pourrait interrompre trop souvent la personne, ou lui donner la sensation qu’on la prive de son autonomie. Autre nuance de taille : le moment où une personne fait des erreurs n’est pas forcément celui où elle souhaite de l’aide ! Leur but ici était donc de se focaliser sur l’interprétation des émotions, pour capter l’instant où l’utilisateur se désengage d’une tâche par frustration, parce qu’il a l’impression qu’il ne va pas y arriver, ou qu’il n’est pas assez sûr de lui.
Pour répondre à cet enjeu, les chercheurs ont pris le parti de se baser sur deux critères : le langage et le regard. L’aspect physique, présentiel du robot, permet plus facilement des interactions non verbales qui sont des clefs de compréhension de l’expression humaine d’un besoin.
Détecter et catégoriser les changements de regard
Pour analyser les différents regards d’un être humain au cours de l’accomplissement d’une tâche, l’équipe a choisi de se baser sur le modèle de Kurylo et Wilson, qui classe les façons de regarder selon plusieurs catégories. Ils ont retenu de leur approche deux types de regards dont ils ont fait la clef de voûte de leur analyse corporelle.
- Le regard mutuel : il est utilisé pour exprimer le désir que l’interlocuteur s’occupe de la même chose que soi.
- Le regard de confirmation : de façon assez similaire, il s’agit du regard qui s’assure que l’interlocuteur est bien en train d’observer la même chose que soi.
Concrètement, ces types de regards se détectent par des changements physiques : par exemple, les yeux qui font des aller-retour entre l’objet et une personne qui pourrait aider, pour solliciter sa validation de façon muette… Certaines études ont montré qu’on pouvait aller de cette façon jusqu’à déterminer quels ingrédients une personne allait mettre dans son sandwich ! Mais cela ne fonctionne bien entendu pas toujours. Une personne peut très bien poser une question sans pour autant regarder ailleurs. Les chercheurs ont donc conclu qu’il fallait créer une approche qui englobe plusieurs systèmes de reconnaissance d’indices sociaux.
Le langage pour exprimer ses besoins
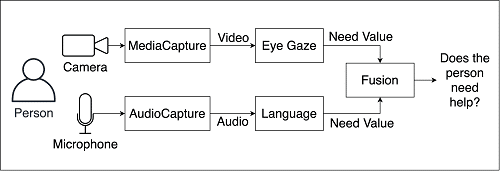
Les scientifiques ont combiné les schémas de regard avec des éléments de langage qui sont associés socialement à un besoin d’aide. Cela peut passer par une expression explicite : « j’ai besoin d’aide ». Plus subtilement, ils ont aussi pris en compte les marques d’hésitations, telles que « je ne suis pas sûr ». De même, les mots interrogatifs, ou encore les négations qui apparaissent souvent à des moments critiques dans l’expression d’un besoin ont été intégrés au modèle.
Dans leur dispositif, tous ces éléments, langagiers et visuels, sont captés par une caméra et un micro : chacun de ces flux d’information est analysé pour déterminer une valeur de besoin. Ensuite, les deux valeurs sont fusionnées pour permettre au robot de décider s’il doit intervenir ou non. Mais il ne s’agit pas d’une simple « addition ». Les chercheurs ont aussi fait en sorte de prendre en compte la temporalité dans laquelle ces signaux interviennent. Par exemple, un bref regard de confirmation suivi d’un « OK », peut signifier que l’utilisateur se demande si la tâche qu’il accomplit est correctement effectuée.
D’autres modèles ont déjà permis de savoir à quel moment un robot devait intervenir dans une tâche donnée. Cependant, ils étaient souvent basés sur la connaissance du robot des tâches à effectuer. Il « savait » donc mécaniquement si la personne faisait une erreur, à quelle étape elle en était, et pouvait interagir en fonction. Tout l’intérêt de cette nouvelle méthode réside dans le fait que les données utilisées ne sont pas spécifiques à une tâche. Elle est donc facilement adaptable à tous types de robots, et permet aussi à la personne aidée de ne pas être aidée si elle n’en sent pas le besoin, et ce même si sa performance n’est pas parfaite.

Un ptérodactyle en lego pour tester le modèle
Pour valider leur modèle, les chercheurs l’ont expérimenté sur 21 personnes. Ces dernières devaient assembler un ptérodactyle en lego à partir d’une simple photo en noir et blanc. Une pièce avait aussi été dissimulée pour augmenter la difficulté. Trois types de réponses de la part du robot étaient possibles en fonction de la parole et du regard du sujet : l’encouragement verbal, le retour indirect et le retour direct. Cette expérimentation à base de lego s’est révélée être un succès, puisque 90% ont trouvé les interventions du robot utile. 86% des participants ont aussi ressenti le fait qu’il était « digne de confiance ».
Afin de vérifier l’adaptabilité du modèle, les scientifiques ont aussi testé le robot sur une personne qui devait fabriquer des cookies, et la transition a été plutôt concluante. À l’avenir, ils aimeraient améliorer leur modèle en intégrant aussi l’analyse des expressions faciales, des mouvements des mains, ainsi que des postures adoptées. Ils souhaiteraient aussi permettre au robot de déterminer un degré d’implication requis, pour ne pas aider une personne plus qu’elle ne le souhaiterait. Laisser aux humains la possibilité de faire les choses «comme des grands», en somme !
La vidéo du test sur la préparation de cookies :