
La nouvelle IA de langage d’OpenAI continue de susciter certaines inquiétudes. Après avoir montré qu’elle était capable de rédiger des dissertations tout à fait convaincantes — permettant potentiellement aux étudiants de « tricher » — et avoir rédigé une publication scientifique sur elle-même en seulement deux heures, cette intelligence artificielle pose un nouveau problème éthique : elle est capable de générer de faux résumés d’articles de recherche, que les scientifiques ne sont pas toujours capables de discerner de résumés originaux. Ceci pourrait compromettre l’intégrité et la précision de la recherche.
Lancé en novembre 2022, ChatGPT peut créer un texte réaliste et intelligent en réponse aux invites de l’utilisateur, quel que soit le sujet. Pour ce faire, il s’appuie sur d’énormes quantités de textes produits par des humains, via lesquels ses concepteurs ont entraîné son réseau de neurones. Des modèles de langage tels que celui-ci sont désormais si sophistiqués qu’ils produisent des textes de plus en plus réalistes, parfois très difficiles à distinguer de textes écrits par l’Homme.
Une récente étude disponible sur bioRxiv a montré en effet « qu’il était étonnamment difficile de faire la différence entre les deux » pour des examinateurs humains. « Je suis très inquiète. Si nous sommes maintenant dans une situation où les experts ne sont pas capables de déterminer ce qui est vrai ou non, nous perdons l’intermédiaire dont nous avons désespérément besoin pour nous guider dans des sujets compliqués », a déclaré Sandra Wachter, qui étudie la technologie et la réglementation à l’Université d’Oxford.
Des résumés originaux, cohérents et convaincants
Afin d’évaluer dans quelle mesure ces textes artificiels étaient « repérables », une équipe dirigée par Catherine Gao, de la Northwestern University de Chicago, a demandé à ChatGPT de générer des résumés de 50 articles de recherche médicale, extraits de cinq revues renommées (JAMA, The New England Journal of Medicine, The BMJ, The Lancet et Nature Medicine). L’invite envoyée au modèle était « Veuillez rédiger un résumé scientifique pour l’article [titre] dans le style de [journal] ».
Les résumés produits ont été évalués à l’aide d’un détecteur de sortie d’intelligence artificielle et d’un détecteur de plagiat (qui donne un score d’originalité de 0 à 100%). Les chercheurs ont également demandé à des examinateurs humains d’identifier parmi un corpus de 25 résumés ceux qui ont été générés par ChatGPT.
L’équipe a par ailleurs vérifié que le format des résumés générés par ChatGPT respectait les exigences de la revue en le comparant aux titres et à la structure de l’article original, puis ont comparé les tailles des cohortes de patients rapportées entre les résumés originaux et générés. Pour commencer, seuls 8 résumés (soit 16%) utilisaient correctement les en-têtes spécifiques à la revue dont ils étaient issus. La taille des cohortes de patients était quant à elle d’un ordre de grandeur similaire entre les résumés originaux et les résumés artificiels. « Il était impressionnant qu’avec seulement un titre et un journal, ChatGPT ait pu générer un résumé superficiellement lisible, avec des thèmes précis et des tailles de cohortes de patients spécifiques à un sujet », écrivent les chercheurs.
Par ailleurs, ChatGPT a su faire preuve d’originalité : presque tous les résumés générés ont été jugés entièrement originaux par le vérificateur de plagiat, avec un score d’originalité médian de 100%. Les résumés originaux ont aussi été soumis à ce contrôle : ils affichaient un score d’originalité médian de 38,5 % — la source du « plagiat » étant systématiquement l’article auquel ils se rapportaient, ce qui est tout à fait normal pour un résumé de recherche.
Deux tiers des résumés artificiels repérés par un détecteur d’IA et par des humains
Le détecteur de sortie d’IA s’est avéré plutôt performant : une forte probabilité de contenus artificiels a été détectée dans les deux tiers des résumés générés par ChatGPT, tandis que les résumés originaux affichaient au contraire une très faible probabilité. L’outil n’est cependant pas infaillible : « 17 (34%) des résumés générés ont reçu un score inférieur à 50% de la part du détecteur de sortie de l’IA, dont 5 avec des scores inférieurs à 1% », rapporte l’équipe.

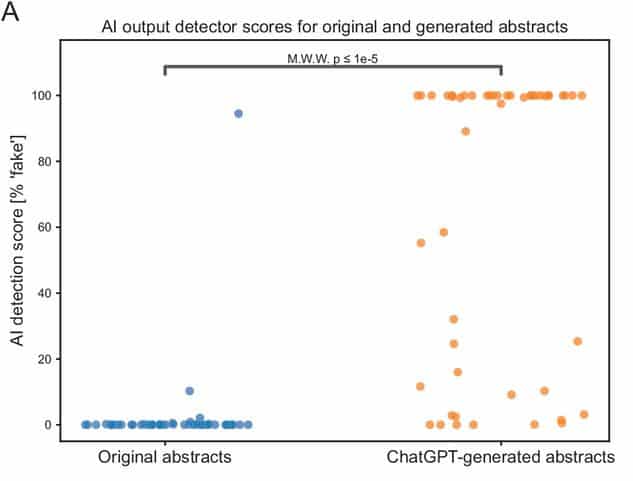
Les examinateurs humains affichent des performances similaires : ils ont correctement identifié 68% des résumés artificiels comme étant générés par ChatGPT et 86% des articles originaux comme étant écrits par des humains. Mais cela signifie tout de même que 32% des résumés artificiels ont été considérés comme des productions humaines et que 14% des résumés originaux ont été pris pour des textes artificiels… Ces examinateurs ont souligné que les résumés qu’ils considéraient comme artificiels étaient généralement « superficiels et vagues ».
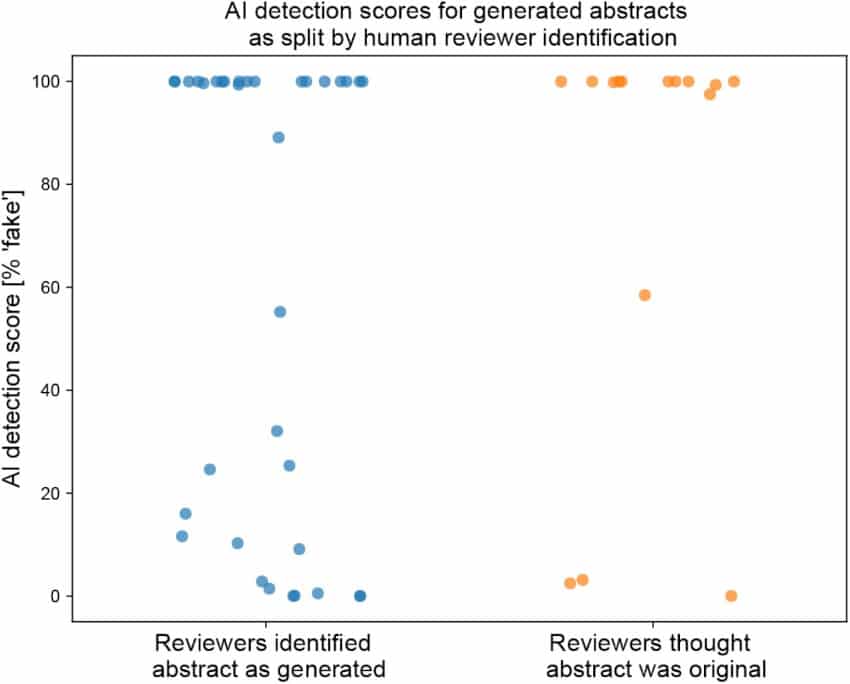
Humains et détecteurs de sortie d’IA peuvent donc identifier la plupart des contenus générés par ChatGPT, mais aucun ne s’est montré infaillible. Les auteurs de l’étude craignent que cette technologie ne soit utilisée de manière contraire à l’éthique. « Compte tenu de sa capacité à générer des résumés avec des chiffres crédibles, il pourrait être utilisé pour falsifier entièrement la recherche », notent-ils. « Cela pourrait signifier que les décisions politiques fondées sur la recherche sont incorrectes », ajoute Sandra Wachter. Les implications sont d’autant plus importantes dans les domaines tels que la recherche médicale, où les fausses informations peuvent mettre en danger la sécurité des personnes.
Mais parallèlement, les chercheurs reconnaissent que son usage peut aussi être vu comme une aide bienvenue, pour « réduire le fardeau de l’écriture et du formatage » ou pour aider les scientifiques à publier « dans une langue qui n’est pas leur langue maternelle ». Par conséquent, Gao et ses collaborateurs suggèrent qu’il soit explicitement mentionné que le texte a été écrit avec ChatGPT lorsque c’est le cas, par exemple en le citant parmi les auteurs. Cependant, les limites de l’utilisation éthique et acceptable des grands modèles linguistiques pour aider à la rédaction scientifique restent à déterminer, concluent-ils.